

The logical model of a relational database is the collection all its tables.
For each table, we specify:
- A name.
- The column names.
- The primary and foreign key constraints.
👉 We don't specify the column types, nor do we specify any integrity constraints, except for the primary and foreign keys.
Derive a logical model from a conceptual model
Rules exist to derive a logical model from the conceptual model.
We explain these rules on the conceptual model shown in the figure below.
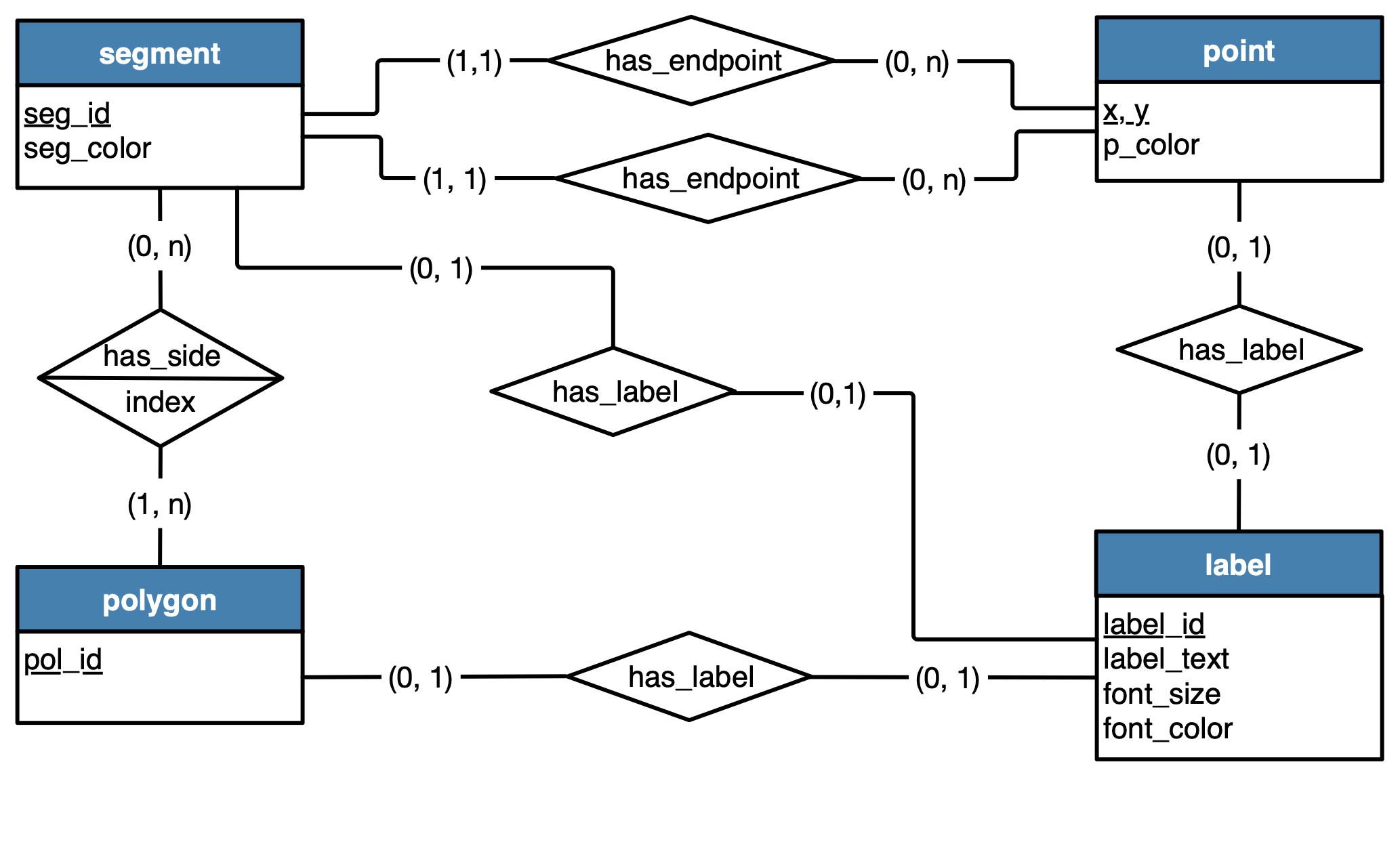
Conceptual model for a database of geometric shapes.
Rules for entities
- Each entity in the conceptual model becomes a table in the logical model.
- A table includes a column for each attribute of the corresponding entity.
- The primary key of a table consists of the columns that are derived from the underlined attributes of the corresponding entity. The underlined attributes in a conceptual model are those that uniquely identify an entity.
Back to our example
Since we have four entities, we obtain four tables.
👉 The underlined columns of a table form the primary key of the table.
segment | (seg_id, seg_color) |
point | (x, y, p_color) |
label | (label_id, label_text, font_size, font_color) |
polygon | (pol_id) |
Rules for one-to-many relationships
Each relationship has cardinalities (min, max) for each entity involved in the relationship (see here for more details).
A one-to-many relationship is one with maximum cardinality 1 on one side and n on the other side.
Given a one-to-many relationship, we change the logical model in the following way:
- In the table corresponding to the entity on the 1 side of the relationship, we create a column for each underlined attribute of the entity on the
nside of the relationship. - The set of these new columns is a foreign key.
Back to our example
The two relationships has_endpoint are one-to-many. Let's consider one of these relationships.
- We create in table
segment(on the 1 side of the relationship) two new columnsx1,y1(corresponding to the two underlined attributes in the entity on thenside). {x1, y1}is a foreign key referencing columns{x, y}in tablepoint.
We repeat the same logic with the second relationship has_endpoint .
- We create in table
segment(on the 1 side of the relationship) two new columnsx2,y2(corresponding to the two underlined attributes in the entity on thenside). {x2, y2}is a foreign key referencing columns{x, y}in tablepoint.
We update the logical schema. The new elements are in bold.
👉 The notation T(a, b), used in the specification of the foreign keys below, denotes the columns a, b in table T.
segment | (seg_id, seg_color, x1, y1, x2, y2) |
point | (x, y, p_color) |
label | (label_id, label_text, font_size, font_color) |
polygon | (pol_id) |
Foreign keys:
segment(x1, y1)referencespoint(x, y)segment(x2, y2)referencespoint(x, y)
Rules for one-to-one relationships
A one-to-one relationship is one where the maximum cardinality is 1 on both sides. It is a special case of a one-to-many relationship.
Back to our example
Consider the relationship has_label between segment and label.
We have two options:
1. We create a new column label_id in table segment.
2. We create a new column seg_id in table label.
If we go for the first option, we might have some NULL values in the column label_id because a segment might have no label.
However, the second option would be worse.
In fact, if we followed the same logic for the other relationships has_label (the one between point and label, and the one between polygon and label), we would end up with three columns in table label: seg_id, polygon_id and point_id. Since a label is attached to either a point, or a segment or a polygon, we would have
NULL values with this solution too. In fact, we would have more NULL values than with the first solution.
👉 Choose the option that minimizes the chances of having NULL values.
We update the logical schema. The new elements are in bold.
segment | (seg_id, seg_color, x1, y1, x2, y2, label_id) |
point | (x, y, p_color, label_id) |
label | (label_id, label_text, font_size, font_color) |
polygon | (pol_id, label_id) |
Foreign keys:
segment(x1, y1)referencespoint(x, y)segment(x2, y2)referencespoint(x, y)segment(label_id)referenceslabel(label_id)point(label_id)referenceslabel(label_id)polygon(label_id)referenceslabel(label_id)
Rules for many-to-many relationships
A many-to-many relationship is one with maximum cardinality n on both sides.
👉 A many-to-many relationship becomes a table in the logical model.
The columns of this new table include:
- All the underlined attributes of the two entities involved in the relationship. These attributes combined form the primary key of the new table.
- All attributes of the relationship.
Back to our example
The relationship has_side is a many-to-many relationship. We create a new table side (note that the name of a table is typically a proper noun) with the following columns: seg_id (underlined attribute of entity segment), pol_id (underlined attribute of entity polygon), index (attribute of the relationship).
{seg_id, pol_id}is the primary key of the tableside.seg_idandpol_idare foreign keys, respectively referencing columnsseg_idin tablesegmentandpol_idin tablepolygon.
We update the logical schema. The new elements are in bold.
segment | (seg_id, seg_color, x1, y1, x2, y2, label_id) |
point | (x, y, p_color, label_id) |
label | (label_id, label_text, font_size, font_color) |
polygon | (pol_id, label_id) |
side | (seg_id, pol_id, index) |
Foreign keys:
segment(x1, y1)referencespoint(x, y)segment(x2, y2)referencespoint(x, y)segment(label_id)referenceslabel(label_id)point(label_id)referenceslabel(label_id)polygon(label_id)referenceslabel(label_id)side(seg_id)referencessegment(seg_id)side(pol_id)referencespolygon(pol_id)
👉 When a table has a composite primary key (one with many columns), it is possible, even recommended, to create a dummy column whose values uniquely identify a row in the table and is chosen as the primary key.
In our example, we can create a column side_id in table side and use it as a primary key.