


- Avec les langages de programmation de première génération, les programmes sont directement écrits avec les instructions machines du processeur.
- Les langages de programmation de deuxième génération utilisent une représentation textuelle (langage d'assemblage) des instructions machines du processeur. Cette représentation textuelle est ensuite convertie en code machine via un assembleur.
- Les langages de programmation de troisième génération sont indépendants du processeur ; on verra plus loin comment ils sont exécutés.




- John von Neumann a apporté d'importantes contributions dans un grand nombre de domaines scientifiques.
- L'architecture de von Neumann est un modèle d'architecture d'ordinateur, elle a comme principale caractéristique l'utilisation d'une unique mémoire, dite centrale, pour stocker les données et les instructions des programmes qui s'exécutent. Elle s'oppose en cela à l'architecture de Harvard.
- Cette mémoire centrale stocke des mots (ensemble de bits) de taille fixe, chaque mot est repéré par sa position que l'on nomme adresse. L'examen d'un mot (la suite des bits à 0 ou à 1) ne permet de savoir ce qu'il représente (une instruction, un entier, ..., ou même une adresse), c'est ce qu'en fait le processeur qui détermine sa sémantique.
- Le fonctionnement d'un processeur n'est pas au programme de ce cours (les étudiants de la mention SL le verront dans le cours Principes de fonctionnement des ordinateurs), mais il est important de savoir que des calculs ne peuvent se faire que sur des données mémorisées dans une mémoire interne du processeur (que l'on appelle registre) : les données à modifier doivent donc être transférées de la mémoire centrale au processeur (chargement ou load), puis en sens inverse du processeur vers la mémoire centrale (rangement ou store).
- Le sigle ISA (pour Instruction Set Architecture) est la spécification externe du processeur : quelles sont les instructions disponibles, les modes d'adressage (c'est-à-dire les différents moyens de spécifier comment accéder aux données), etc.

- Un autre point important à savoir sur le fonctionnement d'un processeur est le mécanisme utilisé pour un appel à un sous-programme.
- Un sous-programme est la traduction au niveau processeur d'une fonction ou d'une méthode : il peut y avoir des arguments et/ou une valeur de retour.
- Pour permettre la récursion, il faut utiliser une pile. Cette pile, dite pile d'exécution, est bien sûr stockée en mémoire centrale.
- Nous allons examiner ici comment se déroule l'appel de la fonction
bar()par la fonctionfoo(). Cette description est simplifiée et conceptuelle : des mécanismes d'optimisation, dont l'utilisation de registres, sont utilisés pour améliorer les performances.
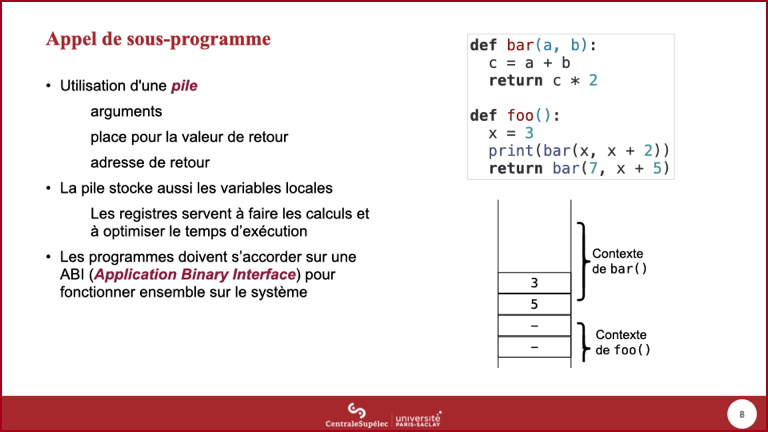
- Les deux arguments du premier appel à
bar()sont évalués, les résultats de ces évaluations sont empilés. - Les paramètres effectifs (ou arguments reçus) sont donc des copies des arguments évalués.
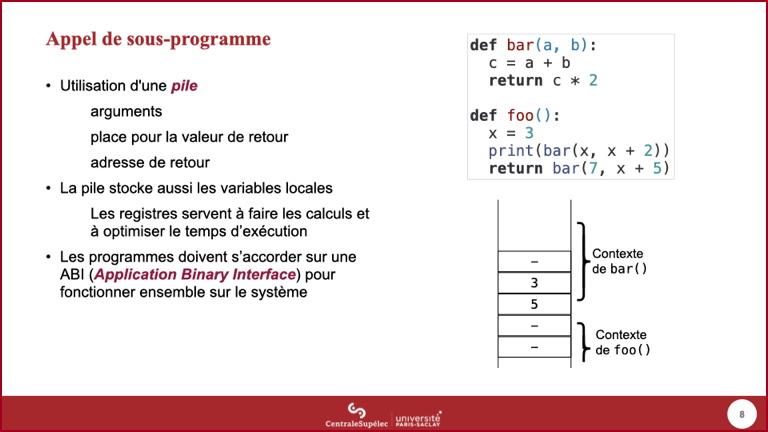
- La fonction
bar()va retourner une valeur, la fonctionfoo()doit donc réserver une place dans la pile pour cela.
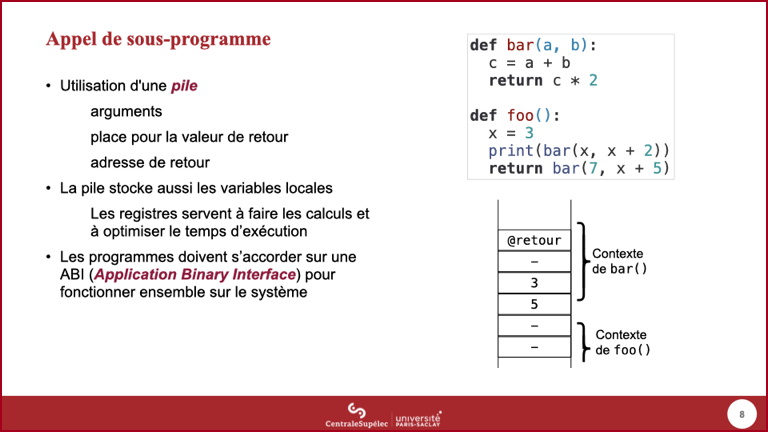
- L'adresse de retour permet au processeur de savoir quelle est l'instruction suivante à exécuter quand l'appel de
bar()est terminé : lors du premier appel debar(), il devra utiliser le résultat comme argument de l'appel àprint(), alors que pour le second appel, le résultat debar()deviendra le résultat defoo().
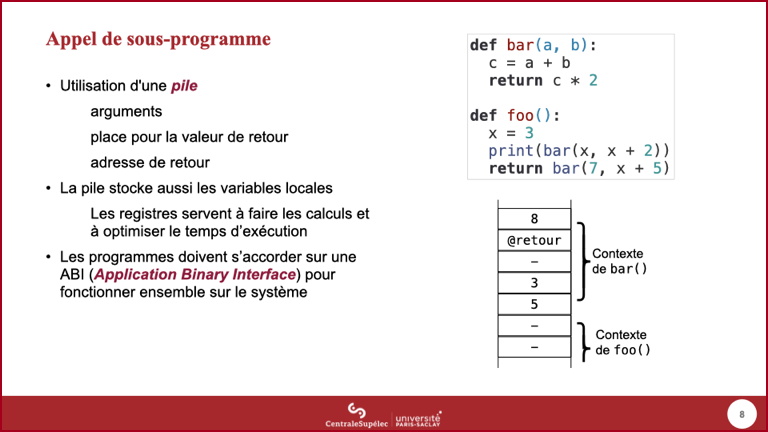
- La fonction
bar()utilise une variable localec: celle-ci est aussi stockée dans la pile. - On note un point important ici : les arguments et les variables locales se comportent donc globalement de façon identique.
- Cette partie de la pile utilisée pour l'appel à
bar()(des arguments aux variables locales) est nommé contexte d'exécution debar().

bar()range dans la place prévue dans la pile la valeur de retour telle que spécifiée par l'instructionreturn.- La valeur de retour est donc une copie du résultat de l'évaluation de l'expression figurant dans l'instruction
return.
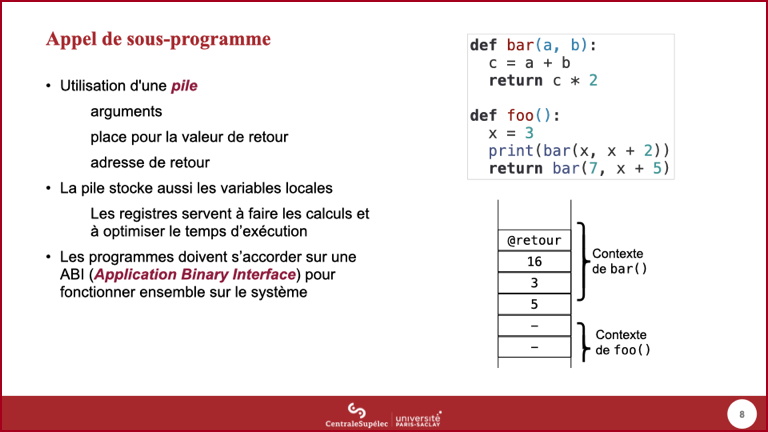
bar()est terminée, sa variable locale est détruite.
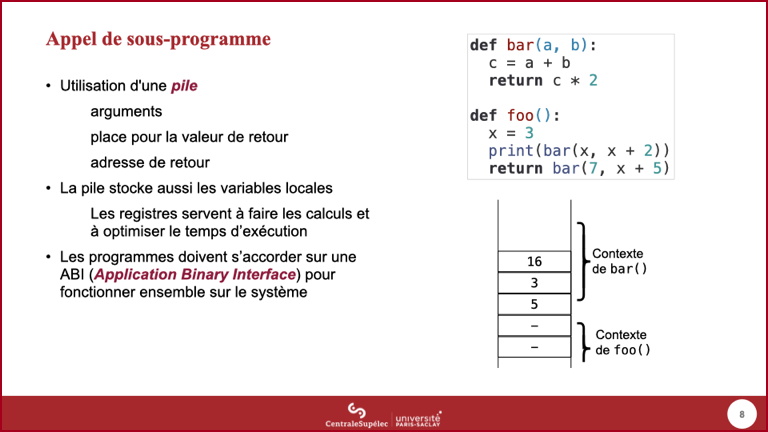
- L'adresse de retour en sommet de la pile permet de revenir dans la fonction
foo().
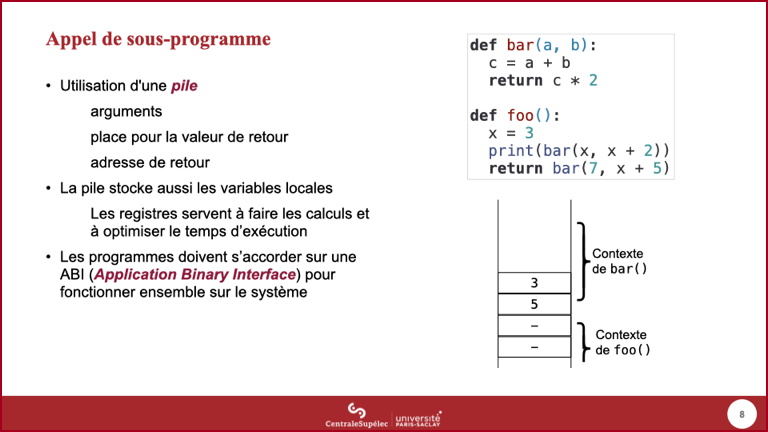
- Celle-ci récupère le résultat ...

- ... et nettoye la pile en supprimant les arguments qu'elle y avait mis.
- La pile retrouve ainsi son état initial.
- Le second appel à
bar()se déroule avec les mêmes règles.

- La définition d'un langage de programmation inclut sa syntaxe (quelles sont les règles d'écriture des instructions) et sa sémantique (quelle sont les effets lorsque ces instructions sont exécutées).
- Si les outils permettant de définir formellement la syntaxe sont maintenant courants, il y a peu de langages ayant une définition formelle de leur sémantique.
- C et C++ définissent leur sémantique en décrivant, en langage naturel, l'effet des différentes instructions sur l'état d'une machine abstraite.
- Il faut aussi noter que, pour ces langages, les standards qui les définissent mentionnent explicitement que certains détails de cette sémantique ne sont pas spécifiés, et peuvent donc dépendre d'une réalisation particulière de cette machine abstraite.

- Il existe deux principales méthodes pour exécuter un programme écrit dans un langage de haut niveau sur un processeur particulier.
- Nous nommerons par la suite exécutable un programme écrit dans le langage de première génération associé au processeur utilisé. Il peut donc être directement exécuté par le processeur.
- Python est un exemple de langage donc l'exécution est classiquement faite par interprétation.
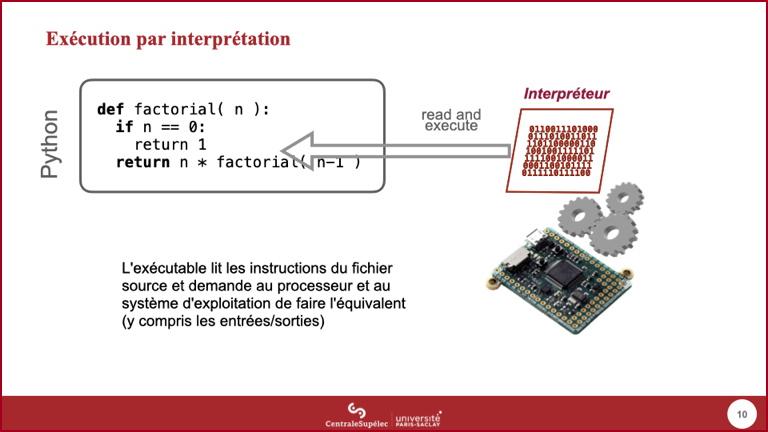
- Dans cette approche, un exécutable, que l'on appelle interpréteur, va aller lire les instructions dans le code source du programme et demander au processeur d'effectuer l'équivalent sémantique de ces instructions.
- Un des avantages de cette approche est que toute modification du code source est directement prise en compte à l'exécution. Un des inconvénients est la relative faible performance des programmes exécutés ainsi. C'est pourquoi les principales bibliothèques Python ayant besoin de performance sont en fait écrites dans un langage compilé, et seule la couche d'accès à cette bibliothèque est écrite en Python.
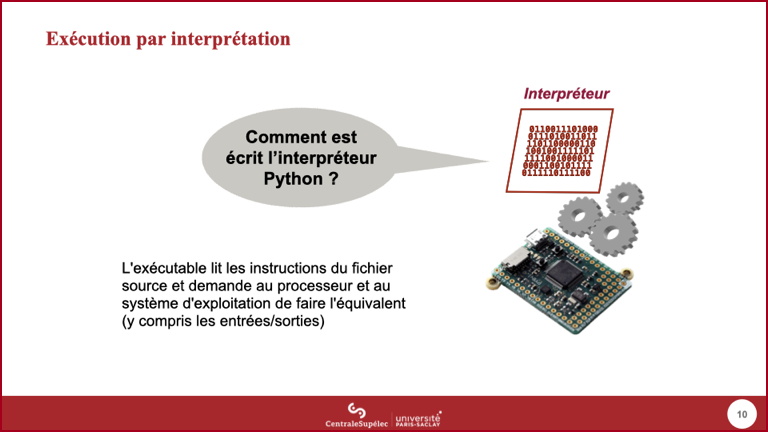
- L'interpréteur Python est un exécutable, donc il n'est pas écrit en Python interprété. Le principal interpréteur Python, CPython, est écrit en C.
- C et C++ sont des exemples de langages donc l'exécution est classiquement faite par compilation.
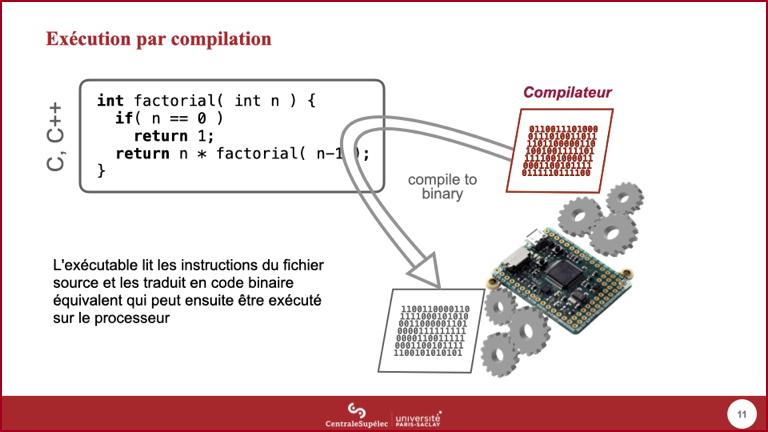
- Dans cette approche, un exécutable, que l'on appelle compilateur, va aller lire les instructions dans le code source du programme et produire du code machine (en langage de première génération) permettant d'effectuer l'équivalent sémantique de ces instructions.
- Le résultat de cette compilation est donc un exécutable, son exécution proprement dite se fait dans une seconde étape, après la compilation.
- Les performances obtenues sont nécessairement meilleures que celles d'un programme interprété car le compilateur ne lira qu'une seule fois le code source et pourra appliquer des optimisations lors de la génération du code machine.
- Par contre, toute modification du code source impose de refaire l'étape de compilation.
- Il est important de noter que le choix entre interprétation et compilation n'est pas directement lié au langage : il existe des compilateurs Python et des interpréteurs C/C++.
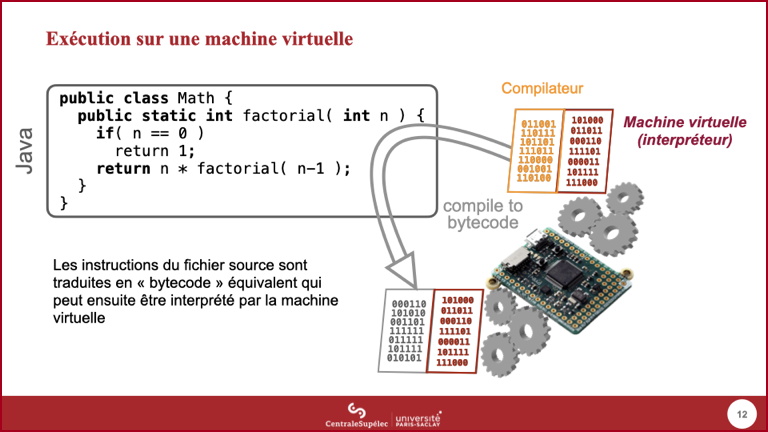
- Par ailleurs, il est assez courant maintenant de mélanger ces deux approches, c'est le cas par exemple pour l'exécution classique de programmes écrits en Java ou en C#.
- Une machine virtuelle est un émulateur de machine dont le processeur, qui a sa propre ISA, n'existe pas physiquement. Les instructions de ce processeur (souvent appelées bytecode) sont de fait interprétées par la machine virtuelle.
- Un programme Java sera lui aussi compilé, mais les instructions générées seront celles de la machine virtuelle Java. Le compilateur Java est lui-même écrit en Java, et exécuté sur la machine virtuelle.
- L'avantage de cette approche est qu'elle permet de s'abstraire des différences entre machines réelles, éliminant ainsi le problème des comportements non spécifiés dans les standards C et C++, tout en profitant des performances apportées par l'étape de compilation séparée.
- La machine virtuelle doit bien sûr être écrite dans un langage compilé, ainsi OpenJDK, la principale plateforme d'exécution pour Java, est écrite en C++.

- Les programmes sont de plus en plus gros (on parle de millions de ligne de code pour un seul programme), il est donc hors de question de stocker un tel programme dans un seul fichier.
- Ce n'est pas un problème pour l'interpréteur, il ira lire le bon fichier au moment où il en a besoin, c'est par contre une difficulté pour un compilateur qui devrait à chaque fois relire tous ces fichiers pour produire l'exécutable même si un seul fichier a été modifié.
- La compilation séparée permet de séparer la compilation de chaque fichier pour produire du code binaire de l'assemblage de ces fichiers binaires pour produire l'exécutable. Cette seconde étape est appelée édition de liens, et sera vue plus loin.
- Un compilateur produit du code binaire pour un processeur, mais ce dernier n'est pas obligatoirement le même que le processeur utilisé pour exécuter le compilateur. Cette compilation croisée est nécessaire pour produire des exécutables pour des micro-contrôleurs ou pour des smartphones.
- Pour améliorer les performances de l'exécution par interprétation, y compris dans le cas d'une machine virtuelle, il existe plusieurs solutions.
- La compilation à la volée s'effectue au moment de l'exécution : un morceau du code source est traduit en code binaire équivalent qui est alors exécuté, il est aussi mémorisé afin de pouvoir être exécuté de nouveau quand le même morceau du code source doit être exécuté de nouveau (cas très fréquent, par exemple avec une boucle).
- La compilation anticipée est utilisée pour traduire du code destiné à être exécuté par une machine virtuelle en code binaire exécutable par un processeur réel, cette traduction est souvent faite au moment du déploiement.

- Il existe de très nombreux langages de programmation, voir par exemple cette liste d'environ 750 langages.
- Fortran est considéré comme le premier langage de troisième génération, il a été conçu par John Backus à partir de 1954 avec dès le départ une orientation vers le calcul scientifique (calcul en virgule flottante).
- Lisp a été conçu à partir de 1958 par le mathématicien John McCarthy, pionnier de l'intelligence artificielle. Ce langage est célèbre pour être basé sur des listes (LISt Processing).
- Algol, avec de nouveau John Backus comme concepteur à partir de 1958, mais aussi Peter Naur, introduit de nombreuses améliorations par rapport à Fortran (programmation modulaire avec des blocs d'instructions, récursivité…) qui seront reprises par de nombreux langages.
- Cobol a été créé à partir de 1959 par un comité mis en place par un département de la défense des États-Unis, avec comme objectif l'écriture d'applications de gestion.
Quelques autres langages méritent d'être signalés pour leurs apports :
- Simula 67 est le premier langage à classes, il a été conçu par Ole-Johan Dahl et Kristen Nygaard au Norwegian Computing Centre avec un objectif de simulation par événements discrets.
- Smalltalk, conçu principalement par Alan Kay, Dan Ingals, et Adele Goldberg au Palo Alto Research Center de Xerox, approfondit l'approche objet (« tout est objet »). Il est compilé vers une machine virtuelle.
- Haskell est un langage fonctionnel typé statiquement, il isole totalement le côté impératif indispensable pour les entrées/sorties.
Ce schéma, et celui-ci, plus complet, présentent les influences entre les différents langages.

Il n'y a pas de critère évident permettant de mesurer l'utilisation d'un langage. Voici quelques liens vers les principaux sites proposant des estimations :
- Tiobe index
- PYPL PopularitY of Programming Language
- GitHub Language Stats
- Stack Overflow Trends
- The RedMonk Programming Language Rankings
- IEEE Spectrum "The Top Programming Languages"
- Top 8 Most Demanded Programming Languages
- Language Communities – An update (Developer Nation)

Ce cours suppose que Python est connu.

- Le langage C a été conçu au Bell Labs par Dennis Ritchie à partir de 1972. Son objectif était de pouvoir remplacer le langage d'assemblage pour écrire une grande partie du système d'exploitation Unix. Il est donc très orienté programmation système.
- Le premier livre décrivant ce langage est connu sous le nom de livre blanc ou K&R. Son évolution est maintenant gérée par un comité commun ISO/IEC.
- Le dernier draft du standard 2023 est disponible ici.
- À noter que le langage C a eu une très grande influence, en particulier syntaxique, sur beaucoup de langages qui sont apparus après (accolades pour les blocs d'instructions, point-virgule à la fin des instructions, == pour la comparaison …).

- Le langage C++ a été conçu par Bjarne Stroustrup, aussi aux Bell Labs.
- Lors de ses études à l'université de Cambridge, Bjarne Stroustrup a travaillé sur les systèmes distribués. Pour cela, il devait faire des simulations, son choix s'est initialement porté sur Simula qu'il a beaucoup apprécié, mais les faibles performances à l'exécution de ce langage l'ont conduit à devoir ré-écrire ses simulations en BCPL.
- C'est pourquoi, lors de son arrivée au Bell Labs, il a souhaité, pour son travail, ajouter au langage C (orienté performances) une couche offrant les abstractions de Simula (classes…).
- Le premier compilateur C++ produisait du code C, ce n'est plus possible avec la définition actuelle du langage (exceptions…).
- Le langage évolue aussi via un comité commun ISO/IEC. Après la version 1998 du standard, la sortie de la version suivante (2011, la version 2003 n'apportait que des modifications mineures) a été retardée à cause du grand nombre de nouveautés. Le comité a donc décidé qu'une nouvelle version du standard serait par la suite publiée tous les 3 ans, les nouvelles fonctionnalités pas encore assez matures étant repoussée à la version suivante.
- Le document sur la norme du langage (sauf la version toute finale, disponible avec un coût auprès de l'ISO), est disponible sur GitHub.
- Un objectif fort pour la conception et l'évolution du langage est que C++ doit être un sur-ensemble de C : tout programme C valide doit être un programme C++ valide, sauf si cela entraine des failles sémantiques.
- Un autre point important est qu'une abstraction introduite dans le langage ne doit pas se traduire par une dégradation des performances quand cette abstraction n'est pas utilisée (« Pay Only For What You Use »).

Afin d'avoir un aperçu rapide de la syntaxe de C et C++, quelques comparaisons avec Python sont présentées maintenant.

- C et C++ sont des langages typés statiquement : il faut préciser dans le code source le type des variables.
- Le mot clef
auto, utilisé ici pour cela, sera présenté par la suite. - La constante donnant la valeur de π est une macro (vue plus tard), elle est écrite en majuscule par convention.
- Il n'y a pas d'opérateur d'exponentiation en C/C++, on utilise une fonction de la bibliothèque standard.

- Les conditions dans les instructions de contrôle doivent être entourées de parenthèses. Le deux-points utilisé en Python ne l'est pas en C/C++.

- Python utilise l'indentation pour identifier les instructions dépendantes d'une instruction de contrôle.
- En C/C++, on utilise un bloc d'instructions pour cela (délimité par les accolades { et }). Quand il n'y a qu'une seule instruction dépendante (par exemple, sur le transparent précédent), le bloc n'est pas obligatoire.
- Pour autant, l'indentation, qui facilite la lecture du code et donc sa compréhension, doit être utilisée.

- Une variable ne peut contenir qu'une valeur appartenant à un type fixé au moment de la définition de cette variable.
- int et double sont des types primitifs. string est un type de la bibliothèque standard C++. auto implique un typage par inférence : le type de
x3est le même que celui de sa valeur d'initialisation, boolean ici.

- En C/C++, les types primitifs sont ceux que le processeur sait directement manipuler. Ainsi, sur une machine où les
intsont stockés sur 32 bits (cas le plus courant), il n'est pas possible d'initialiser une variable de ce type avec une valeur ne pouvant pas être représentée correctement sur 32 bits (soit entre {$-2^{31}$} et {$2^{31}-1$}). - Le suffixe l permet de préciser que le litéral doit être interprété comme un
long(en général 64 bits).

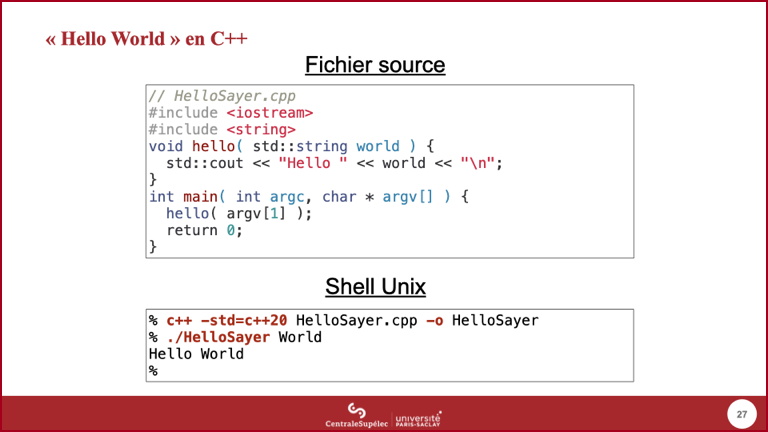
- Afin d'avoir un premier aperçu d'un programme complet en C/C++, nous montrons ici un classique Hello world (tradition initiée par le « livre blanc » !), avec une variante ici : le deuxième mot est obtenu sur la ligne de commande.
- La version Python sert de base de comparaison.
- Quand on execute un fichier Python en ligne de commande, la variable spéciale
__name__vaut__main__pour ce fichier uniquement. Les arguments sur la ligne de commande sont alors accessibles via la listesys.argv.

- Un programme C ou C++ commence son exécution par la fonction
main(). Cette fonction reçoit en paramètres les arguments de la ligne de commande via un tableau de chaînes de caractères (habituellement nomméargv, la présence de l'étoile sera expliquée au cours suivant) ; le premier paramètre, habituellement nomméargc, est la taille de ce tableau. voidindique que la fonctionhello()ne retourne rien,worldest un tableau de caractères, soit une chaîne de caractères en C.printf()est la fonction standard en C pour l'affichage sur la sortie standard (elle est déclarée dans le fichier d'entêtestdio.h), elle utilise une approche basée sur une chaîne de format, sa description complète figure ici. Le caractère\nreprésente un passage à la ligne suivante.- Nous utilisons ici une exécution par compilation, le plus courant en C. cc est le compilateur, l'option -o permet de spécifier le nom de l'exécutable créé.
- Après compilation, on peut donc exécuter cet exécutable.
- C++ propose sa propre bibliothèque standard d'entrées/sorties (mais celle de C peut être utilisée).
- Cette bibliothèque se base sur la notion de flux :
cout, dans l'espace de nomsstd(voir plus loin) représente le flux de sortie standard, il est déclaré dans le fichier d'entêteiostream. - Cette bibliothèque utilise la surcharge des opérateurs, mécanisme qui sera vu dans un cours ultérieur : il n'est pas nécessaire de comprendre comment marche ce mécanisme pour une utilisation basique de cette bibliothèque.
- On utilise ici le type
stringde la bibliothèque standard C++, qui est compatible avec les tableaux de caractères du monde C. - L'appel du compilateur C++ inclut une option lui demandant d'être conforme au standard 2020 du langage.

- Les trois programmes commentés, ainsi qu'un très simple Hello world en C, sont disponibles dans le dépôt Git.

- Les langages de programmation permettent d'organiser le code source d'un programme sous la forme de différents fichiers ayant des liens entre eux. Ce mécanisme est en général intégré au langage, et prévoit une organisation hiérarchique en lien avec le système de fichiers.
- La terminologie utilisée est très variable selon les langages, mais les termes de paquetage, module, paquet sont courants.
- Le concept d'espace de noms (unicité d'un nom à l'intérieur d'un espace, possibilité d'utiliser le même nom dans des espaces distincts) est souvent lié à ces mécanismes.
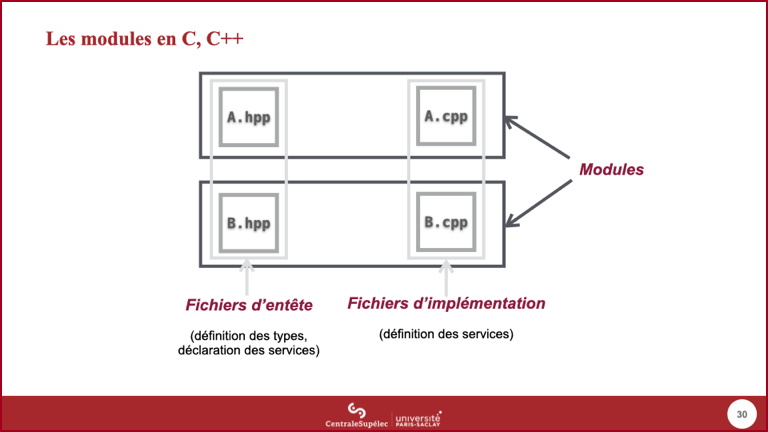
- C (et C++ dans une certaine mesure) n'offre pas de tel mécanisme au niveau du langage.
- Nous utiliserons le terme module pour désigner un composant offrant des services pouvant être utilisés par d'autres composants.
- Un tel module doit décrire les services offerts, et fournir ces mêmes services. La déclaration de ces services se fait dans un fichier d'entête, ayant par convention une extension
.h(pour header), la réalisation de ces services dans un ou plusieurs fichiers d'implémentation (extension.c) qui peuvent être compilés de manière séparée. - En C++, les conventions de nommage des fichiers sont plus variées : on utilise classiquement
.ccou.cpppour les fichiers d'implémentation,.hh,.hppou simplement.hpour les fichiers d'entête.
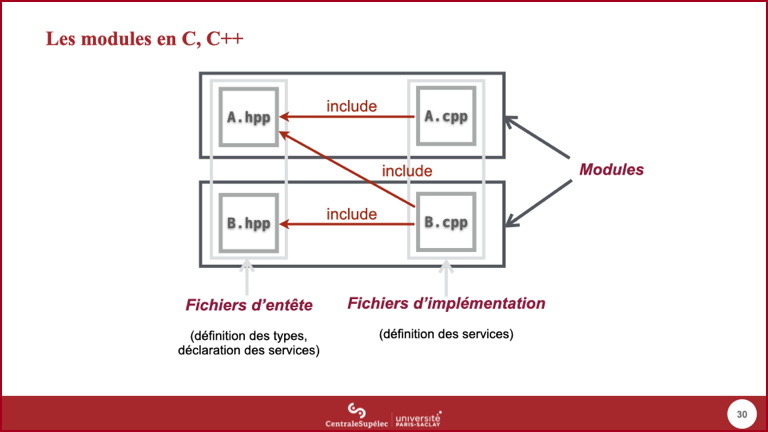
- Le ou les fichiers d'implémentation d'un module doivent inclure le fichier d'entête de ce même module pour permettre au compilateur de vérifier que l'implémentation est conforme à la déclaration.
- Un module qui a besoin des services d'un autre module inclura aussi le fichier d'entête de cet autre module.

- Cette étape d'inclusion de fichiers n'est pas faite par le compilateur, mais par un outil qui est automatiquement déclenché avant la compilation.
- Cet outil s'appelle le préprocesseur, il ne connait rien aux langages (il est d'ailleurs utilisé par d'autres langages que C ou C++), il ne s'intéresse dans le code source qu'aux lignes qui commencent pas le caractère
#(que l'on nomme directives). - Selon le mot clef qui suit, il va effectuer différentes actions dans le code source :
- Avec
include, il va remplacer la ligne par le contenu du fichier nommé : si<et>entourent le nom du fichier, il s'agit d'un fichier d'entête système, le compilateur lui a indiqué dans quel répertoire il trouvera ce fichier ; si"est utilisé, il s'agit d'un fichier d'entête utilisateur, le préprocesseur le trouvera dans le répertoire courant, ou dans un autre qui a été indiqué sur la ligne de commande de compilation (option-I). - Avec
define, il s'agit de la définition d'une macro (simple ici) : le préprocesseur remplacera dans le code source toute occurence du nom qui suitdefine(que l'on nomme symbole, utilisant par convention uniquement des majuscules et le caractère_) par ce qui figure sur la suite de la ligne. C'est, en C, une des façons standards de définir une constante nommée. En C++, on utilisera avec raison le mot clefconstpour définir des constantes.
- Avec
Les directives du préprocesseur ne sont pas des instructions du langage C (qu'il ne connait d'ailleurs pas), donc il n'y a pas de point-virgule à la fin.
- C++, à partir de la version 2020 du standard, offre le support des modules au niveau du langage, ce point ne sera pas abordé dans ce cours.
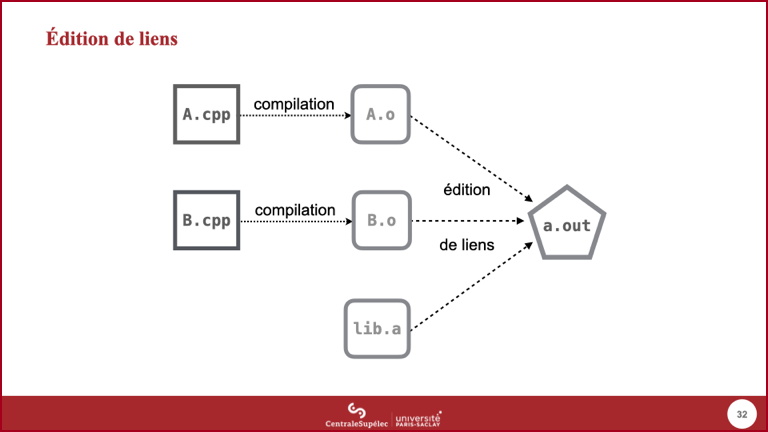
- Ce mécanisme permet effectivement la compilation séparée de chaque module. Celle-ci va produire pour chaque fichier d'implémentation un fichier binaire (contenant du code machine) qui n'est pas encore un exécutable car un exécutable doit avoir une et une seule fonction
main(). On nomme le fichier binaire produit fichier objet (extension.osur Unix,.objsur Windows). - L'étape d'assemblage des différents fichiers objets pour obtenir un exécutable s'appelle éditions de liens : il s'agit en effet d'établir les liens entre les appels d'une fonction dans un module et la définition de cette fonction dans un autre module ou dans une bibliothèque du système d'exploitation.
- Cette étape est automatiquement exécutée après la compilation, et sans conservation du fichier objet, sauf si l'option
-cest utilisée (dans ce cas, le fichier objet est créé). L'outil en charge de l'édition de liens se nomme en généralld(linker), mais il est préférable de ne pas l'utiliser directement car le compilateur connait les très nombreuses options qu'il doit lui fournir. Par ailleurs, le compilateur sait reconnaître les fichiers objets, et s'il n'y a pas de fichiers sources à compiler, il se contente d'appeler l'éditeur de liens directement.

- Un exemple de programme, utilisant un module séparé, est disponible dans le dépôt Git. Les différentes étapes (préprocesseur, compilateur, éditeur de liens) y sont mises en évidence.
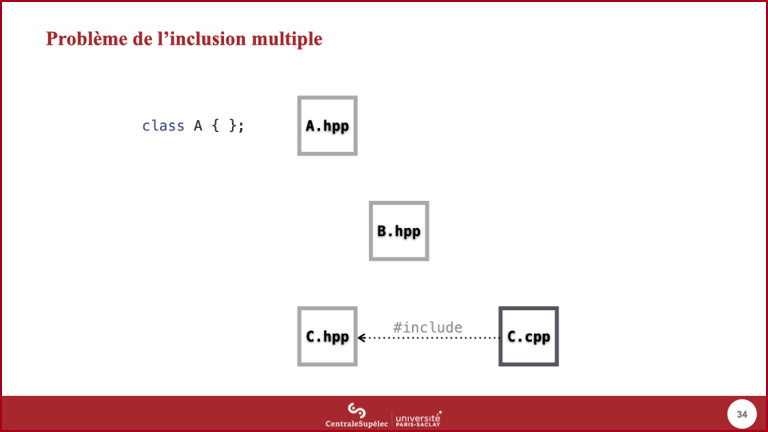
- Ce mécanisme de gestion des modules par un outil externe au compilateur (le préprocesseur) a pour conséquence le problème connu sous le nom d'inclusion multiple.
- L'exemple pour illustrer ce problème utilise 3 modules :
A,BetC. - Le module
Adéfinit un typeA(grâce au mot clefclassqui sera vu dans un cours ultérieur). La définition de ce type doit être dans le fichier d'entête puisqu'il est destiné à être utilisé par d'autres modules.
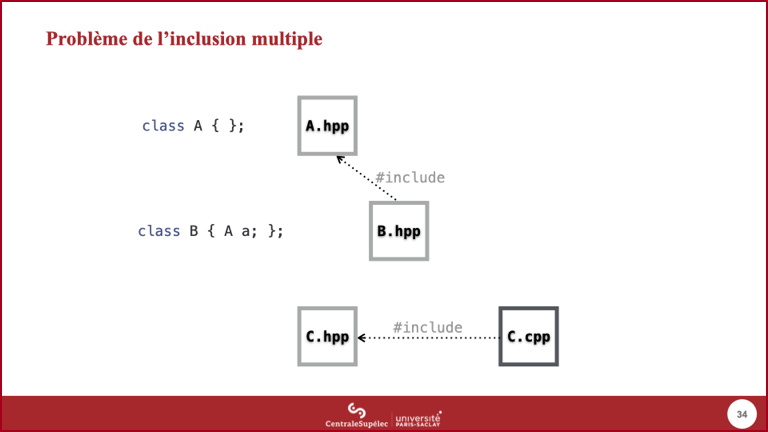
- Justement, le module
Ba besoin d'utiliser ce typeApour définir son propre typeB. - Donc le fichier d'entête de
Bdoit inclure le fichier d'entête deA.
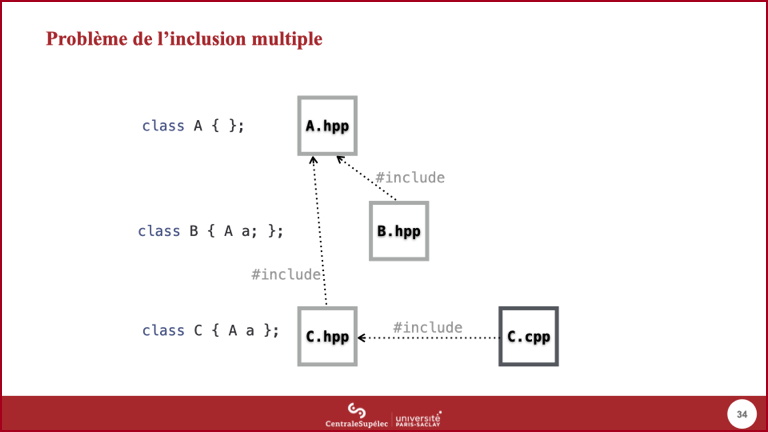
- De même, le module
Cdéfinit un typeCutilisant lui aussiA.
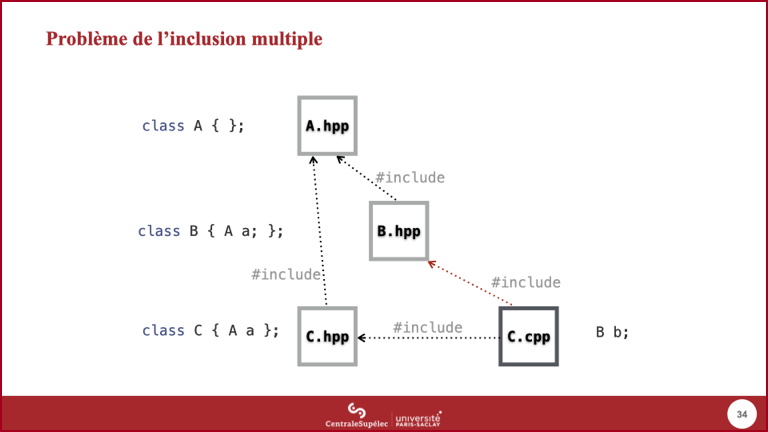
- Supposons maintenant que le fichier d'implémentation de
Cait besoin d'utiliser un élément de typeB: il doit donc inclure le fichier d'entête deB. - Lors du traitement par le préprocesseur du fichier d'implémentation de
C:- L'inclusion de son propre fichier d'entête va inclure indirectement le fichier d'entête de
A. - Puis l'inclusion du fichier d'entête de
Bva provoquer une deuxième inclusion du fichier d'entête deA.
- L'inclusion de son propre fichier d'entête va inclure indirectement le fichier d'entête de
- Dans le fichier fourni au compilateur par le préprocesseur, il y aura donc 2 définitions du type
A, ce qui est interdit par le langage.

- Le problème étant localisé au niveau du préprocesseur, la solution a y apporter se fait aussi au niveau du préprocesseur.
- Le principe se base sur l'utilisation d'un symbole basé sur le nom du module ou du fichier.
- Quand le préprocesseur traite la première inclusion, ce symbole n'est pas défini,
ifndef(if not defined) est vrai, donc le préprocesseur continue, définit le symbole (il n'y a pas besoin de lui donner une valeur), traite le contenu du fichier jusqu'auendifà la fin du fichier. - Lors de la seconde inclusion, le symbole est défini, donc tout ce qui se trouve entre
ifndefetendifest ignoré. - Un symbole peut être marqué comme défini sur la ligne de commande avec l'option
-D. Ainsi, une autre utilisation classique du préprocesseur est de faire de la compilation conditionnelle, par exemple pour n'activer du code qu'en mode développement.
La directive suivante
#pragma once
qui ne fait pas partie du standard, est cependant reconnue par la majorité des environnements de compilation actuels, elle remplace avantageusement le mécanisme décrit ci-dessus pour apporter une solution au problème de l'inclusion multiple.

- Le dépôt Git montre l'exemple du problème de l'inclusion multiple.


- Pour terminer avec le préprocesseur, quels autres points :
- Les macros peuvent avoir des paramètres (mais cela peut devenir techniquement très compliqué), la généricité en C++ remplace une grande part de ces besoins de macros avec paramètres.
- Il existe quelques opérateurs connus du préprocesseur.
- Il est possible d'indiquer qu'un symbole n'est plus défini.
- Quelques symboles sont prédéfinis.
- Les modules C et C++, tels que décrits ci-dessus, ne sont pas des espaces de noms.
- C++ propose un mécanisme de création et d'utilisation des espaces de noms totalement indépendant des modules.
- Les espaces de noms sont organisés hiérarchiquement, la racine étant l'espace de noms global.

- Les différentes possibilités de faire référence à un nom défini à l'intérieur d'un espace sont montrées ici.

- L'ensemble de la biblioth!èque standard C++ est dans l'espace de noms
std. - Comme il n'existe pas de tels espaces de noms en C, toute la bibliothèque standard C est accessible au niveau global.
- Afin de limiter cette pollution de l'espace de noms global, C++ propose pour chaque fichier d'entêtre standard C un fichier d'entête équivallent mais qui offre les services correspondants dans l'espace de noms
std.


- Les fonctions d'entrée/sortie de la bibliothèque standard C sont déclarées dans le fichier d'entête
stdio.h(standard input output). printf()a déjà été rapidement évoquée pour afficher sur la sortie standard.- La fonction la plus générale est
fprintf(), dont le premier argument indique le flux de sortie (stdoutcorrespond à la sortie standard). - Dans la chaîne de format,
%dindique qu'il faut afficher une entier dont la valeur est l'argument suivant defprintf()non encore utilisé. - La documentation complète est ici.
- La lecture sur l'entrée standard (
stdin) se fait avec la fonctionfscanf().
Dans l'appel à fscanf(), la variable lue doit être précédée de &, ceci sera expliqué dans le cours suivant.
- Celle-ci retourne le nombre de variables correctement lues.
- La documentation complète est ici.

- Bjarne Stroustrup a décidé de faire une autre bibliothèque standard d'entrées sorties pour C++ car :
- celle de C n'est pas extensible à de nouveaux types,
- la chaîne de format est interprétée, ce qui est plutôt contraire à un objectif de performance.
- La surcharge des opérateurs
<<et>>, qui sera vue dans un prochain cours, est utilisée par cette bibliothèque. - On parle d'extraction à partir d'un flux d'entrée (qui sera faite en fonction du type de la variable lue), et d'émission vers un flux de sortie (là aussi, prise en compte du type).

- Le dépôt Git contient ces 2 exemples.

© 2025 CentraleSupélec