


- Nous avons vu dans le premier cours que les données, dans l'architecture Von Neumann, sont stockées en mémoire centrale. Le processeur peut modifier ces données grâce à une opération d'écriture (store).
- L'approche impérative est directement liée à ce fonctionnement : l'opération qui la caractérise est l'affectation dans une variable qui modifie ainsi l'état du processus qui s'exécute.

- On voit clairement sur cet exemple la modification de la variable
ivia l'instruction d'affectation=.

- Dans les langages de troisième génération, les données sont typées, ce qui défini en particulier le nombre de mots nécessaires pour les stocker en mémoire centrale.
- Les langages proposent quelques types de base comme les entiers, les flottants… (types primitifs) et permettent au programmeur de définir de nouveaux types (types utilisateurs).
- Une donnée stockée en mémoire centrale possède donc une adresse, deux données distinctes ont donc des adresses différentes.
- Une variable permet à un programmeur de définir une donnée en lui donnant un nom, et permet l'accès à cette donnée en utilisant ce nom.

- L'association entre une variable et sa donnée existe sous deux formes :
- soit la variable est associée de manière fixe à la donnée, et donc l'accès à cette donnée ne peut se faire que via cette variable,
- soit la variable est associée à un lien vers la donnée (typiquement l'adresse), ce lien peut changer (la variable sera alors associée à une autre donnée) et peut aussi être partagé avec d'autres variables (permettant ainsi l'accès à une même donnée par plusieurs variables).

- Le processeur n'utilise pas les mêmes instructions pour ajouter des entiers et pour ajouter des flottants, ces instructions dépendent aussi de la taille de la donnée (flottants sur 32 ou 64 bits…).
- Les interpréteurs ou compilateurs des langages de troisième génération doivent donc connaître les types des données manipulées pour activer les bonnes instructions du processeur. Il existe deux approches :
- soit l'information de type est associée à la donnée, cette information n'est prise en compte qu'à l'exécution, et des erreurs peuvent alors être détectées à ce moment : on parle de typage dynamique.
- soit l'information de type est associée à la variable, et le compilateur (ou l'interpréteur) interdit toute affectation dans cette variable par une valeur d'un type non conforme : on parle de typage statique.
- Le typage statique peut être explicite (le programmeur doit spécifier le type d'une variable), ou par inférence (le type d'une variable est fixé par sa valeur d'initialisation).

- C et C++ sont des langages typés statiquement, le type d'une variable doit être précisé avant son nom.
- L'initialisation en C utilise l'opérateur d'affectation.
- Cette syntaxe (avec un typage explicite) est bien sûr possible en C++, mais déconseillée pour des raisons de conversions implicites.
- La syntaxe C++ utilisant des parenthèses est basée sur la syntaxe pour passer des arguments au constructeur d'une classe, elle est maintenant aussi déconseillée, sauf dans les cas où l'utilisation d'accolades implique une liste d'initialisation.
- Cet article conseille d'utiliser systématiquement le typage par inférence en C++.



- Quand le langage C a été inventé, les machines différaient par la taille des mots en mémoire, aussi le langage n'a pas imposé la taille en nombre de bits des entiers, des flottants… Le standard impose par contre un ordre sur le nombre de bits utilisés par les différents types d'entiers (un
intutilise au moins autant de bits qu'unshort) et de flottants. - Un
charcorrespond à la plus petite entité adressable en mémoire (un octet sur les machines actuelles). - Un
intcorrespondait initialement à la taille d'un entier manipulé naturellement par le processeur, il est par exemple passé de 16 à 32 bits quand les processeurs 32 bits sont apparus, mais il n'a pas franchi l'étape suivante de 64 bits. - Par défaut, les entiers sont signés, le qualificatif
unsignedpermet de ne manipuler que des nombres positifs ou nuls. - La représentation des nombres négatifs n'est pas plus standardisée par le langage, même si la représentation en complément à 2 est la seule encore utilisée.
- Les littéraux sont par défaut des
intou desdouble, des suffixes permettent de changer le type d'un littéral. - Le fichier d'entête
stdint.h(cstdinten C++) permet d'utiliser des types explicites quant à la taille des entiers et la représentation des nombres négatifs. - En C, le fichier d'entête
stdint.h

- Ce fichier dans le dépôt Git montre la taille des différents types primitifs.


- Une variable permet d'accéder à une donnée stockée en mémoire centrale, cette donnée a donc une adresse ; celle-ci est accessible en C et en C++ grâce à l'opérateur
&(adresse de). - Le type de l'adresse d'une donnée est dépendant du type de la donnée (l'adresse d'un
intet l'adresse d'undoublesont de types différents), c'est pourquoi le terme de pointeur est utilisé. - Il est possible de définir des variables de sorte pointeur, on accède à la donnée pointée grâce à l'opérateur
*(indirection).

- Ce fichier dans le dépôt Git montre l'utilisation d'un pointeur.

- Une variable de sorte pointeur contient donc un lien (une adresse) vers une donnée ; on a aussi besoin d'indiquer qu'une telle variable, à certains moments, ne pointe pas sur une donnée : on parle de pointeur nul (
nullptren C++,NULLen C). - Un pointeur stocké dans une variable est lui-même une donnée, on peut donc accéder à son adresse... On a rarement besoin de plus de deux niveaux d'indirection en C ; en C++, d'autres mécanismes permettent souvent de ne pas avoir besoin de ce deuxième niveau.
- Un pointeur générique, non typé, est parfois nécessaire en C : il est compatible avec tout type de pointeur, le standard n'assure la correction du code que si ce pointeur est reconverti dans son type initial.

- Ce fichier dans le dépôt Git montre l'utilisation de pointeur de pointeur, ainsi que l'erreur d'exécution quand on fait une indirection sur un pointeur nul.

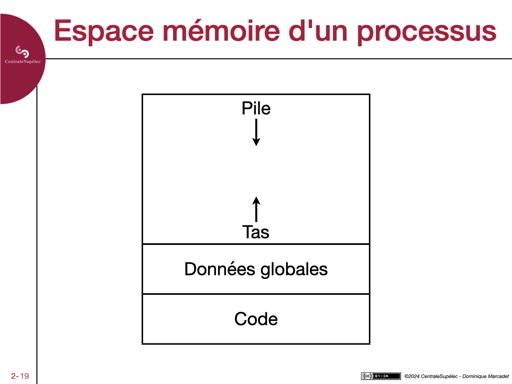
- On a vu que les données sont stockées en mémoire centrale. L'espace mémoire d'un processus est constitué de plusieurs zones :
- Une zone contient les instructions du programme qui s'exécute, cette zone est souvent en lecture seule et sa taille est connue du système d'exploitation quand le processus est créé.
- Une zone contient les données définies en dehors de toute fonction ; la taille de cette zone est aussi connue.
- Une zone est utilisée par la pile d'exécution (cf le mécanisme d'appel de sous-programme présenté au premier cours), on a vu que les arguments et les variables locales y sont stockées ; la taille nécessaire à cette zone dépend de la profondeur des appels aux sous-programmes…
- Une dernière zone (heap en anglais) est utilisée par le programmeur quand il a besoin d'espace pour stocker des données ; la taille nécessaire à cette zone n'est pas non plus connue du système d'exploitation quand le processus est créé.
- Le schéma montre qu'il est possible d'avoir ces quatre zones dans un espace mémoire unique, au risque d'une collision entre la pile et le tas. Les mécanismes de gestion mémoire des processus dans les systèmes d'exploitation actuels sont évidemment nettement plus compliqués, mais le principe qu'il existe trois zones différentes où des données peuvent être stockées reste valide.

- On parle d'allocation statique quand une donnée est stockée dans la zone globale.
- En C et C++, il s'agit de variables définies en dehors de toute fonction, ou de variables locales (définies à l'intérieur d'une fonction) qui sont qualifiées avec le mot clef
static.

- La définition d'une variable implique la réservation de la zone mémoire nécessaire à mémoriser la donnée associée.
- Il est parfois nécessaire de pouvoir mentionner l'existence d'une variable sans la définir : une déclaration permet ceci, le mot clef
externest utilisé pour cela.


- On parle d'allocation automatique quand une donnée est stockée dans la pile.

- On parle d'allocation dynamique quand une donnée est stockée dans le tas.

- C'est l'opérateur
newqui déclenche une allocation dynamique en C++, le résultat est un pointeur sur la zone mémoire allouée. - C'est au programmeur, en C et en C++, d'indiquer à l'environnement d'exécution qu'un bloc mémoire alloué dynamiquement n'est plus nécessaire pour la suite de l'exécution, l'opérateur
deleteest utilisé pour cela en C++. - En C, l'allocation dynamique est gérée par des fonctions de la bibliothèque standard, en particulier
malloc()etfree(). L'argument demalloc()est la taille, en nombre dechar, de la zone mémoire à allopuée, l'opérateursizeofpermet d'obtenir cette information. - On parle souvent, par abus de langage, de destruction d'un bloc mémoire, il faut bien comprendre que ce bloc mémoire est simplement redonné à l'environnement d'exécution pour être réutilisé ultérieurement, et que les transistors ne sont pas détruits !


- Tous les langages ne permettent pas de choisir un type d'allocation parmi les trois possibles, C et C++ sont parmi les rares langages qui offrent ce choix.

- Dans de nombreux langages, le programmeur n'a pas besoin de libérer la mémoire qui a été allouée dynamiquement et qui n'est plus nécessaire, c'est l'environnement d'exécution qui s'en charge quand il s'aperçoit qu'un bloc mémoire n'est plus utilisé ; ce mécanisme est appelé ramasse-miettes.
- Ce n'est pas le choix fait pour C et C++ car ce mécanisme a obligatoirement des conséquences sur la performance des programmes.

- Ce fichier dans le dépôt Git montre différents points liés à l'allocation.

- Les valeurs numériques figurant dans le code source d'un programme, à part peut-être
0,1et-1, ont une signification, il est donc indispensable de les nommer afin d'expliciter cette sémantique et d'améliorer la qualité du logiciel. - Le mot-clef
constpermet de préciser qu'une variable ne sera plus modifiée après son initialisation : toute tentative est signalée comme une erreur par le compilateur. - En C++, une telle variable est aussi une expression constante, et peut être utilisée quand le langage impose une telle contrainte (par exemple après un
casedans unswitch). constexprpeut aussi être utilisé avec des fonctions.



- Les conversions répondent à différents besoins, c'est pour les identifier plus facilement dans le code source que C++ offre ces notations.
volatileindique que la variable qualifiée peut être modifiée de manière asynchrone par rapport au fil d'exécution courant.

- Un tableau est une suite contiguë d'éléments de même type.
- Les tableaux basiques peuvent être alloués statiquement, automatiquement ou dynamiquement.
- En C++, il faut utiliser les tableaux de la bibliothèque standard (dont
std::vector), sauf si une raison particulière justifie l'utilisation de tableaux basiques. - Le premier indice valide est 0, il n'y a pas à l'exécution de vérification de la validité de l'indice en C et C++ (surcoût qui ne doit pas être imposé à ceux qui n'en ont pas besoin).


- On peut obtenir un pointeur sur n'importe quel élément d'un tableau : le pointeur indique une position dans un tableau.
- La différence entre deux positions est une distance (un nombre d'éléments, de type
ptrdiff_tqui est une variante d'entier). - On peut ajouter ou soustraire une distance à une position, on obtient une autre position.
- On comprend qu'ajouter des positions n'a pas de sens.

- Quand on alloue dynamiquement un tableau basique d'entiers, on récupère un pointeur sur un entier (et non un pointeur sur un tableau d'entiers) qui s'utilise pourtant comme si c'était un nom de tableau : cela montre la proximité entre tableaux et pointeurs.


- Ce fichier dans le dépôt Git montre l'utilisation des tableaux basiques, celui-ci montre l'utilisation de
std::vector.

- Une chaîne de caractères en C est un tableau basique de caractères. Le caractère de code 0 (noté
'\0') permet de signaler la fin de la chaîne (qui n'est pas obligatoirement la fin du tableau). - En C++, le type
std::stringest à utiliser de manière préférentielle pour ne pas avoir à s'occuper du bon dimensionnement des tableaux utilisés par les chaînes basiques de C.

- Ce fichier dans le dépôt Git montre montre quelques utilisations de chaînes de caractères.


- Les énumérations existent en C, mais avec un typage assez faible et une visibilité directe des constantes dans l'espace de noms courant.
- Les
enum classde C++ apportent une solution à ces problèmes.


- En C et C++, un agrégat peut bien sûr être au choix alloué statiquement, automatiquement ou dynamiquement.


- Ce fichier dans le dépôt Git montre montre quelques utilisations d'un agrégat.


- L'expression à gauche d'une affectation doit correspondre, une fois évaluée, à une zone mémoire accessible et modifiable.

- Un nom de variable n'existe pas au niveau du processeur.

- Une lvalue reference non constante doit être initialisée avec une lvalue.
rietisont deux noms pour la même donnée, et cette association ne peut plus être modifiée ensuite.- Un type ne sert pas seulement à déclarer des variables, il est aussi utilisé pour qualifier les paramètres d'une fonction ou sa valeur de retour : c'est dans ce cadre que l'intérêt des références sur valeur gauche (parfois abrégé en références gauches) apparait.
- Il existe aussi des références sur valeur droite qui seront vues plus tard.

- Ce fichier dans le dépôt Git illustre la très faible utilité des références sur valeur gauche pour la simple définition de variables.

© 2024 CentraleSupélec