



- Puisqu'une fonction n'a pas d'effet de bord, un compilateur peut lancer en parallèle plusieurs appels : dans un contexte de processeurs multi-cœurs, c'est une possibilité intéressante.
- De même, l'appel d'une fonction avec les mêmes arguments conduira au même résultat, ce qui offre des possibilités d'optimisation.
- Les entrées/sorties ne sont possibles que par effets de bord, donc un langage de programmation ne peut pas être uniquement fonctionnel.

- Cette version de la fonction
longueur_tableau()rend le même service que la version itérative vue dans le chapitre précédent. Mais elle n'utilise pas l'affectation, donc est fonctionnelle.

- Ce fichier dans le dépôt Git montre les versions itérative et récursive de la fonction
longueur_tableau().


- La version post-fixée est utile pour des utilisations avancées de la généricité.

externest optionnel puisque le point-virgule (à la place de l'accolade ouvrante) suffit pour indiquer qu'il s'agit d'une déclaration et pas d'une définition.

- Le paramètre
idef1()peut être modifié (car nonconstici) de la même façon que la variable localek. Mais toute modification est faite sur la copie qui a été empilée, donc cette modification ne survit pas au retour def1().

- Le programmeur qui utilise
f2()sait quejpeut être modifié car il doit passer son adresse comme argument (la modification potentielle est visible sur le site d'appel).

ietjreprésentent la même donnée en mémoire : au niveau du processeur, ceci n'est possible que si c'est l'adresse de j qui est effectivement mis dans la pile d'exécution.- Le programmeur qui utilise
f3()ne sait quejpeut être modifié qu'en allant regarder la déclaration deg3()(la modification potentielle n'est pas visible sur le site d'appel).

- Un passage par valeur impose la recopie de l'argument dans la pile : ce n'est pas pénalisant pour un entier, mais ça l'est pour une donnée de taille importante. L'utilisation d'une référence constante sur valeur gauche permet de conserver l'écriture et la sémantique d'un passage par valeur tout en profitant des performances du passage par adresse.

- Ce fichier dans le dépôt Git montre ces différentes versions de passage d'arguments.

- On aurait pu écrire plus simplement
return d * d;, ce qui montre bien que c'est l'évaluation de l'expression figurant dans lereturnqui est copié dans la pile.

tabest alloué statiquement, donc continue d'exister en dehors de la fonctiongetTab().




- Comme le nom des fonctions est présent dans un fichier objet (afin que l'éditeur de liens puisse effectivement faire ces liens entre appels et définition d'une fonction), cela implique que le compilateur C++ va coder le nom et le type des paramètres dans le nom apparaissant dans un fichier objet ; cette possibilité de surcharge n'existe pas en C : afin de conserver la compatibilité entre ces deux langages, il est nécessaire de préciser au compilateur C++ qu'une fonction est une fonction C et non pas C++. Cela se fait via la directive
extern "C"en préfixe d'une déclaration d'une fonction C.

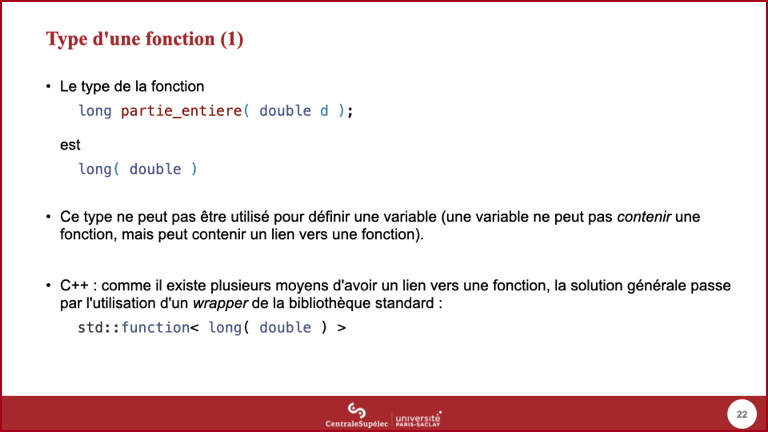


- Les parenthèses autour de
*pfsont nécessaires pour que*s'applique à la variablepfet non au type de retourlong.

- Voir la documentation de cette fonction ici.




- La valeur d'une variable capturée par valeur est prise lors de la définition de la fonction lambda.
- La valeur d'une variable capturée par référence est prise lors de l'exécution de la fonction lambda.
- Par défaut, la capture se fait par valeur. Voir ici une description complète.
- La durée de vie d'une variable capturée par référence doit excéder celle de la fonction lambda.

- Ce fichier dans le dépôt Git montre des exemples d'utilisation de fonctions anonymes.

- Lien vers l'article Wikipédia en anglais.

- Dans un appel de fonction synchrone, la fonction appelante est bloquée tant que la fonction appelante n'a pas terminée son exécution (ou, dans le cas d'une coroutine, tant que celle-ci n'a pas atteint un point de suspension).
- Quand la fonction appelée effectue une opération longue sans solliciter le processeur (typiquement, une opération d'entrée/sortie), il y a une sous-utilisation du processeur.
- Dans un appel asynchrone, la fonction appelante reprend son exécution sans attendre la fin de la fonction appelée. Il faut dans ce cas un mécanisme annexe permettant à la fonction appelante de savoir si la fonction appelée a terminé son exécution (est de récupérer le résultat le cas échéant). Il en existe plusieurs par exemple :
- la fonction appelante reçoit lors du premier appel un identifiant de l'opération demandée, identifiant qui peut être utilisé ensuite pour savoir si l'opération est terminée,
- la fonction appelante fournit un callback à la fonction appelée.
- Une autre solution consiste à exécuter l'opération longue dans un second thread, il faut alors mettre en place un mécanisme de synchronisation entre le thread principal et le thread chargé de l'opération longue : voir le cours Programmation Système.
- Le mécanisme des coroutines offre une autre solution : lors de l'exécution de l'opération longue, la coroutine associée est suspendue, d'autres peuvent donc s'exécuter :
- cette solution nécessite un support de l'environnement d'exécution,
- même si des threads sont utilisés en interne par cet environnement, ce n'est pas nécessairement visible du programmeur qui n'a donc pas à se charger des aspects liés à la synchronisation ; c'est le principe retenu en particulier par Node.js,
- Les mots clefs async/await sont souvent utilisés pour combiner l'synchronisme et les coroutines.
- Les générateurs sont une application classique des coroutines, mais il y a pas d'asynchronisme associé.



- Ce fichier dans le dépôt Git montre un exemple basique de coroutine.

- Ce fichier dans le dépôt Git montre un générateur basé sur une coroutine.

- Le problème du traitement des erreurs est toujours compliqué et dépend beaucoup du contexte et du domaine concerné. Bjarne Stroustrup en parle dans cette conférence.



© 2025 CentraleSupélec