


Le concept d'agrégat a été formalisé par Charles Antony Richard Hoare sous le nom de record class. Ce document mentionne en particulier les pointeurs sur de tels agrégats (nommés références), les références nulles, l'allocation dynamique, et la spécialisation (par exemple, une expression est soit une constante avec une valeur, soit une variable avec un nom, soit un opérateur binaire avec 2 opérandes qui sont des expressions).
Ces idées ont été reprises par Ole-Johan Dahl et Kristen Nygaard et mises en œuvre dans la version 1967 du langage Simula ; ce langage est considéré comme le premier des langages à objets, il a introduit de nombreuses idées (méthodes, protection, objet courant…) que l'on retrouve dans les langages actuels.
Smalltalk est connu pour avoir poussé très loin l'approche objet : les classes sont elles-même des objets.

L'approche objet n'est pas limitée aux langages de programmation. Elle s'applique aussi aux phases amonts d'un cycle de développement logiciel, avec un langage de modélisation comme UML.
Ce transparent et les suivants présentent les concepts objets indépendamment d'un langage particulier.








Bjarne Stroustrup avait comme objectifs, quand il a conçu le langage C++ comme une extension objet du langage C :
- d'ajouter les concepts de classes et d'héritage sans nuire à la performance,
- de ne pas imposer de surcoût à ceux qui n 'utilisent pas telle possibilité du langage (« Pay only for what you use »),
- de conserver au maximum la compatibilité avec C,
- de limiter l'ajout de nouveaux mots clés (un nouveau mot clef rend potentiellement incompatible un programme écrit en C qui utiliserait ce mot comme identifiant),
- de permettre aux programmeurs de définir de nouveaux types qui puissent s'utiliser aussi facilement que les types existants ; en particulier, l'allocation dynamique n'est pas imposée aux objets, contrairement à des langages comme Java ou C#.
Il a par ailleurs introduit une terminologie qui diffère un peu de celle classique de l'approche objet ; ainsi, les attributs sont nommés données membres, les méthodes fonctions membres.

- Cet exemple est choisi pour illustrer les points d'attention et présenter les concepts et bonnes pratiques lors de la définition de classes en C++. Il existe bien sûr une classe stack dans la bibliothèque standard C++, classe qu'il est fortement conseillé d'utiliser si un besoin d'une telle structure de données existe.
- La protection est mise en œuvre à l'aide de labels. Par défaut, en l'absence d'un tel label, les membres sont privés (accessibles uniquement par les méthodes de la classe) avec le mot clef
classalors qu'ils sont publics (accessibles par tout le monde) avec le mot clefstruct. À ce détail près, les deux mots clés sont équivalents, mais le mot clefclassest plus parlant. - Le choix fait ici est de stocker les éléments de la pile dans un tableau basique alloué dynamiquement ; on verra plus tard comment choisir la taille de ce tableau, elle est fixée dans ce premier exemple à
10. Ce choix d'un tableau basique est bien sûr un mauvais choix (sauf contrainte particulière, std::vector ou une variante doit être utilisé si on a besoin d'un tableau en C++) ; il est fait pour illustrer les points d'attention pour la définition de classes en C++. - Un utilisateur de notre classe
Pilea besoin de connaitre sa taille en mémoire pour créer une instance, c'est pourquoi la définition d'une telle classe se trouve habituellement dans un fichier d'entête. Par contre, le code des méthodes va être compilé, il est donc habituellement dans le fichier d'implémentation associé.

- Il faut préciser que l'on définit ici la méthode
empile()de la classePile, pas d'une autre classe : on retrouve l'opérateur de spécification de contexte::déjà vu avec les espaces de noms. - L'objet courant, ou objet récepteur, est connu de la méthode courante par l'intermédiaire du mot clef
this, qui est un pointeur constant ; il aurait été plus logique que l'objet courant soit connu via une référence sur valeur gauche, mais celles-ci n'avaient pas encore été introduites dans le langage au moment de la définition de la syntaxe des classes et méthodes C++. - Quand un interpréteur ou un compilateur rencontre un identifiant, il doit déterminer quelle est la donnée associée à ce nom : on parle de résolution de noms. L'idée générale est de raisonner en terme de contextes imbriqués : la recherche commence dans le contexte courant ; en cas d'échec, le compilateur passe au contexte englobant, et ainsi de suite jusqu'au contexte global (ou contexte racine). Par exemple, quand le compilateur trouve l'identifiant
taille_, il regarde dans le contexte courant, la méthode : il n'y a ni variable locale, ni paramètre avec un tel nom, donc il passe au contexte englobant, la classe ; dans ce contexte, il trouve un attribut avec ce nom, donc la recherche s'arrête car la donnée associée à ce nom a été trouvée. Lethis->est donc ici non nécessaire, il est présent comme illustration.

- Le mot clef
inlinedemande au compilateur de remplacer l'appel de la fonction ainsi qualifiée (avec l'empilement des arguments, de la place pour la valeur de retour, de l'adresse de retour...) par le corps de cette fonction, ce qui améliore les performances. Ce n'est pas toujours possible, en particulier avec les fonctions récursives. - La définition d'une telle fonction, déclarée
inline, doit bien sûr être vue lors de la compilation d'un code l'utilisant, c'est pourquoi elle doit se trouver dans le fichier d'entête. - Si la définition d'une méthode est donnée lors de sa déclaration, cette méthode est automatiquement
inline.

- Ce fichier dans le dépôt Git montre cette première version de notre classe
Pile.

- Un constructeur est une méthode particulière chargée d'initialiser un objet lors de sa création, son nom est le nom de la classe.
- Il ne faut pas indiquer de type de retour (ni même
void), et il ne doit pas y avoir d'expression dans une éventuelle instructionreturn. - Il peut avoir des arguments, donc une classe peut avoir plusieurs constructeurs (surcharge).
- Dès qu'il existe au moins un constructeur, son utilisation est obligatoire. S'il n'existe pas de constructeur dans une classe, un constructeur par défaut (sans argument) est généré par le compilateur, il initialisera les attributs soit avec les valeurs d'initialisation indiquées dans la définition de la classe, soit en appelant le constructeur par défaut correspondant au type de l'attribut.
- Le destructeur est la méthode inverse du constructeur, son nom est le nom de la classe précédé du caractère
~. - Si le destructeur n'est pas défini pour une classe, un destructeur est généré automatiquement, il appèlera le destructeur de chaque attribut (un type primitif, y compris un pointeur comme
tab_, n'a ni constructeur, ni destructeur). - Le destructeur est appelé automatiquement quand un objet est détruit (après la dernière instruction de
main()pour une variable allouée statiquement, à la sortie du bloc pour une variable allouée automatiquement, lors de l'utilisation dedeletepour une variable allouée dynamiquement). - Il ne peut pas avoir d'argument, et ne doit pas spécifier de type de retour.
tab_a été alloué comme tableau basique dans le constructeur, donc est de type pointeur sur flottant. À l'exécution, il n'est pas possible de savoir sitab_pointe sur un seul flottant, ou sur un tableau de flottants (sauf à mémoriser une information complémentaire, ce qui serait contraire à « Pay only for what you use »). C'est donc le programmeur qui doit savoir si, derrière un pointeur, il y a un tableau alloué dynamiquement (et dans ce cas, il doit utiliserdelete[]), ou un simple élément.

- L'idiome RAII décrit la bonne pratique pour l'utilisation des constructeurs et destructeur : un constructeur doit acquérir les ressources dont a besoin l'objet, le destructeur les libère.
- La ressource la plus classique est la mémoire, allouée dynamiquement dans un constructeur : le destructeur se charge de la libérer, c'est ce qui est fait pour notre classe
Pile. - La majorité des autres langages n'a pas ce concept de destructeur car la mémoire dynamique est gérée automatiquement (ramasse-miettes, garbage collector).
- Pourtant, la mémoire n'est pas la seule ressource dont un objet peut avoir besoin, deux exemples avec des classes de la bibliothèque standard l'illustrent.
- Un
ifstreamreprésente un fichier accédé en lecture, le constructeur se charge de demander au système d'exploitation d'ouvrir le fichier, le destructeur se charge de demander sa fermeture : on ne peut pas oublier de le faire. - Le constructeur d'un
lock_guardne rendra la main qu'après avoir acquis le mutex (cf. second cours de programmation système), le destructeur libèrera le mutex : de nouveau, pas d'oubli possible.

- Ce fichier dans le dépôt Git montre l'appel des constructeur et destructeur de notre classe
Pile.

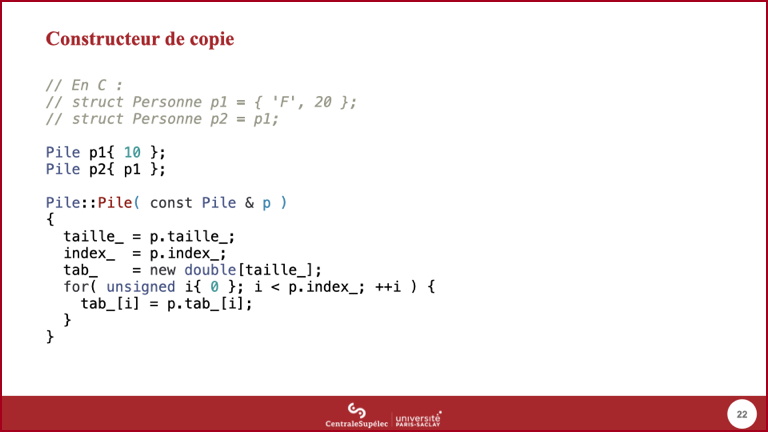
- Un agrégat C peut être initialisé à partir d'un agrégat existant. Ce même comportement doit donc être possible, automatiquement, avec un objet C++.
- Donc l'initialisation de
p2à partir dep1est acceptée par le compilateur avec notre version actuelle dePile, ce qui signifie que le constructeur correspondant, appelé le constructeur de copie, a été généré automatiquement par le compilateur. - Cette version générée automatiquement appelle les constructeurs de copie des attributs ; pour les types primitifs, y compris les pointeurs, c'est une simple recopie de la valeur qui est effectuée.
- Le pointeur
tab_dep1va donc être recopié dans l'attributtab_dep2, ce qui signifie quep1etp2vont utiliser le même tableau : ce n'est clairement pas une bonne idée. - Il faut donc définir un bon constructeur de copie pour notre classe
Pile. Ce constructeur reçoit donc un argument de typePile. - Un passage par valeur n'est pas possible : une copie de
p1devrait être empilée, et le constructeur de copie est nécessaire pour faire cette copie ! - Un passage par adresse conduirait à avoir des objets qu'on ne pourrait pas utiliser comme les agrégats.
- Le passage par référence sur valeur gauche solutionne ce problème ; le coté constant n'est pas obligatoire, mais il n'y a en général aucune raison de modifier l'objet que l'on va copier.
- Le code du constructeur de copie se contente de faire la copie, mais en prenant soin de créer un nouveau tableau.

- Ce fichier dans le dépôt Git montre la nécessité du constructeur de copie pour notre classe
Pile.

- Un agrégat C peut être recopié dans un autre agrégat. Ce même comportement doit donc être possible, automatiquement, avec un objet C++.
- Donc la copie de
p2dansp1est acceptée par le compilateur avec notre version actuelle dePile, ce qui signifie que la méthode correspondante, appelée le l'affectation par copie, a été générée automatiquement par le compilateur. - Cette version générée automatiquement appelle les affectations par copie des attributs ; pour les types primitifs, y compris les pointeurs, c'est une simple recopie de la valeur qui est effectuée.
- Le pointeur
tab_dep2va donc être recopié dans l'attributtab_dep1, ce qui signifie que l'ancien tableau dep1va devenir inaccessible (fuite de mémoire), et quep1etp2vont utiliser le même tableau : ce n'est toujours pas une bonne idée. - Il faut donc définir un bon comportement d'affectation par copie pour notre classe
Pile. - Ce comportement est déclenché par l'opérateur
=: il est possible, en C++, de surcharger les opérateurs existants, ce point sera vu plus en détail dans un cours ultérieur. Cette surcharge s'obtient par la définition d'une fonction (libre ou membre) dont le nom estoperatorsuivi du ou des caractères constituant l'opérateur. - Pour le cas de l'affectation, la fonction membre est obligatoire. Cette méthode reçoit donc un argument de type
Pile, nous pouvons utiliser un passage par valeur (le constructeur de copie sera utilisé pour cela) ou par référence sur valeur gauche, à priori constante. - On peut considérer que le code de l'affectation par copie est constitué du code du destructeur (on détruit la représentation actuelle de
p1), puis celui du constructeur de copie (on ré-initialisep1à partir dep2), c'est ce qui est fait ici. - On commence par vérifier que l'argument reçu par référence n'est pas l'objet courant (sinon, on va détruire l'objet courant et essayer de le re-construire à partir de ... plus rien !).
- Classiquement, l'affectation par copie retourne l'objet courant par référence non constante : le standard C++ prévoit en effet que
t1 = t2est une valeur gauche sit1ett2sont des types primitifs ou des agrégats.

- La définition de l'affectation par copie sous la forme du destructeur suivi du constructeur par copie est fragile, en particulier si une exception est émise lors de l'allocation du nouveau tableau.


- Une bonne pratique est d'utiliser l'idiome du
swap(): cette méthode est chargée d'échanger la représentation de l'objet courant avec celui reçu en argument, et peut être utile dans d'autre contextes. - L'affectation par copie peut être alors facilement écrite en utilisant ce
swap(): si une exception est émise lors de la construction detmp, l'objet courant restera dans un état connu et cohérent.


- Ce fichier dans le dépôt Git montre la nécessité de l'affectation par copie pour notre classe
Pile.


- Il est possible de préciser que certains attributs d'un objet sont constants, c'est-à-dire qu'ils ne sont plus modifiables après avoir été initialisés.
- Dans l'exemple de
Pile, un choix de conception pourrait être : la taille de la pile est fixée lors de sa création, et ne peut plus être modifiée ensuite. - Les attributs
taille_ettab_(le pointeur, pas le contenu du tableau) peuvent alors être déclarés constants. - Les comportements de copie (construction et affectation) ne sont alors plus possibles.

- C++ permet aussi de préciser qu'une fonction membre est constante, c'est-à-dire qu'elle ne modifie pas l'objet récepteur.
- Décider qu'une méthode ne change pas l'objet est un choix de conception, l'utilisation de
constpermet donc de traduire ce choix dans le code, ce qui améliore la traçabilité. - Le compilateur vérifiera cette non-modification ; d'ailleurs, dans une fonction membre constante, non seulement
thisest un pointeur constant, mais il pointe aussi sur un objet constant. constest post-fixé, sinon il s'appliquerait au type de retour.constfait partie de la signature de la méthode : il est possible d'avoir deux méthodes avec le même nom et les mêmes paramètres si l'une est constante et pas l'autre.

- Si un attribut est constant, il est interdit de lui affecter une valeur ; c'est pourtant ce qui est actuellement fait dans le constructeur afin de l'initialiser.
- Une solution possible est d'utiliser la syntaxe d'initialisation classique au moment de la définition de l'attribut (c'est ce qui a été fait dans la première version de la classe
Pile). Mais cette solution ne peut pas prendre en compte les arguments passés au constructeur. - Dans certains langages, comme Java, l'affectation dans un attribut constant est autorisée dans un constructeur.
- En C++, le choix s'est porter sur une solution syntaxique qui permet de différentier une initialisation (lors de la création de l'attribut) d'une affectation (l'attribut à déjà une valeur).
- Cette syntaxe est bien sûr aussi autorisée pour les attributs non constants.
- Tout attribut qui n'est pas initialisé via cette syntaxe aura une initialisation par défaut (voir plus loin) suivie d'une éventuelle affectation dans le corps du constructeur.


- L'initialisation par défaut est celle effectuée quand aucune valeur n'est donnée au moment de la définition de la variable.
- Pour les types primitifs, aucune valeur initiale n'est donnée à l'attribut (sauf les variables globales, initialisées à
0,false,nullptr). - Pour les types utilisateurs :
- Si aucun constructeur n'est défini, un constructeur par défaut est généré, il effectuera une initialisation par défaut des attributs.
- S'il existe un constructeur par défaut, il sera utilisé.
- S'il existe un ou plusieurs constructeurs, mais pas le constructeur par défaut, une erreur sera signalée.
- Le constructeur par défaut est en particulier nécessaire pour pouvoir créer des tableaux d'objets.
- Un moyen d'obtenir un constructeur par défaut est de donner des valeurs par défaut à tous les paramètres d'un constructeur existant.

- Ce fichier dans le dépôt Git montre la version de notre classe
Pileavec une taille constante et un constructeur par défaut.


- Afin d'avoir un type utilisateur qui puisse s'utiliser « les yeux fermés » aussi facilement qu'un type primitif, et ceci sans aucun problème, il est nécessaire que les 4 comportements utilitaires indiqués soient corrects.
- Pour autant, faire en sorte que tous les types utilisateurs respectent cette forme canonique n'est pas un objectif ; le point important est de se poser la question.
- Différentes situations peuvent se présenter :
- Le comportement utilitaire généré automatiquement est correct : rien à faire. Par exemple, en utilisant un
std::vectorpour notre classePileau lieu d'un tableau basique, les 4 comportements générés auraient été naturellement corrects. - Le comportement utilitaire généré automatiquement est incorrect mais nécessaire : il faut le définir afin qu'il soit correct.
- Le comportement utilitaire généré automatiquement est incorrect mais non nécessaire ; par exemple, dans le cas d'un singleton, il est inutile de vouloir définir des comportements de copie corrects. Il faut alors s'assurer que le comportement généré mais incorrect ne soit pas utilisé par erreur.
- Le comportement utilitaire généré automatiquement est correct : rien à faire. Par exemple, en utilisant un

- Il est possible de demander au compilateur de ne pas générer l'un des comportements utilitaires avec cette syntaxe, certes inhabituelle (mais on retrouvera une variante plus tard dans le cadre de l'héritage), mais qui a comme avantage de ne pas nécessiter un mot clef supplémentaire.
- On peut aussi choisir de dire explicitement que la version générée automatiquement est celle retenue.


- Un constructeur avec un argument est un moyen de construire une instance (ici de la classe
Nombre) à partir d'une valeur (ici de typeint). On peut considérer que c'est un moyen de convertir unintenNombre, c'est ce que fait le compilateur. - Ici, l'appel de
foo()se fait avec un argument de typeint; le compilateur ne trouve aucune fonction avec cette signature, par contre il a vu la définition defoo()prenant unNombre, ainsi que la possibilité de construire une instance deNombreà partir d'unint. Ainsi, il va créer une temporaire de typeNombregrâce au constructeur, appelerfoo()avec cette temporaire, et après, bien sûr, détruire la temporaire. - Cette conversion implicite, via le constructeur, peut se justifier quand les types concernés appartiennent au même domaine (ce que l'on peut supposer ici).

- Dans d'autres cas, cette conversion implicite n'est pas souhaitable : par exemple, doit-on permettre la conversion implicite d'un entier en
Pile? - Le mot clef
explicitpermet d'interdire au compilateur de faire de telles conversions implicites. - Il reste toujours possible de faire la conversion explicite en créant soi-même la temporaire.


- En C++, de même que dans la très grande majorité des autres langages orientés objets, les classes ne sont pas des objets, ne sont pas instances d'une méta-classe ; les classes n'existent que dans le code source.
- Il est cependant possible d'avoir des attributs et méthodes de classe, c'est à dire des attributs et méthodes qui ne concernent pas un objet particulier, mais qui concernent la classe vu comme l'ensemble de ses instances.
- Le mot clef
static(qui a d'autres significations dans d'autres contextes) est utilisé pour cela. - Il n'y a bien sûr pas d'objet récepteur (pas de
this) dans une méthode de classe. - Il est ainsi très facile, en C++, de connaître à tout instant le nombre d'instances d'une classe (il faudrait bien sûr aussi prendre en compte le constructeur de copie).
- Le qualificatif
inlineici permet de n'avoir qu'une seule définition de l'attributnb_instances_même si le fichier d'entête est inclus plusieurs fois.
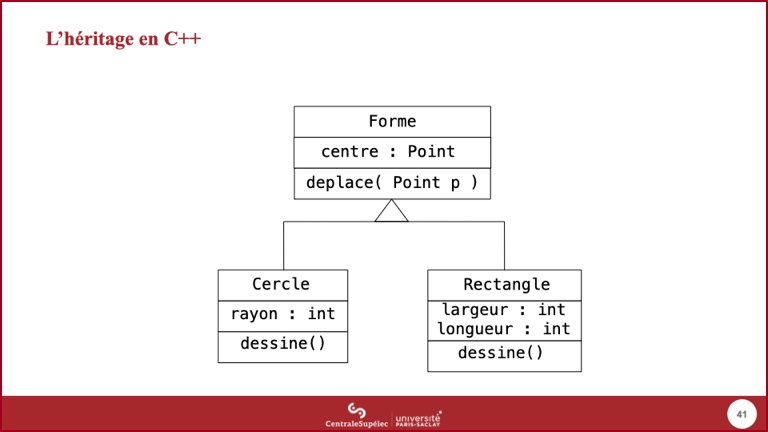
- Pour présenter la mise en œuvre de l'héritage en C++, nous utiliserons ce mini domaine présenté sous la forme d'un diagramme de classes UML.
- Notre application souhaite manipuler des cercles et des rectangles. Pour certains comportements, elle n'a pas besoin de savoir si c'est un cercle ou un rectangle, simplement que c'est une forme.
- La classe
Formemémorise donc uncentre, ce qui permet d'offrir le comportement de déplacement. - La sous-classe
CerclespécialiseForme:- Héritage structurel : une forme a un centre, un cercle est une forme, donc un cercle a un centre.
- Héritage comportemental : une forme peut être déplacée, un cercle est une forme, donc un cercle peut être déplacé.
- Outre le centre, un cercle doit mémoriser un rayon ; il peut ainsi proposer un service d'affichage.
- La description de la classe
Rectanglesuit le même principe (on ne considèrera que les rectangles avec des côtés horizontaux et verticaux). - La question « pourquoi pas des ellipses et des rectangles, ou des cercles et des carrés » sera examinée plus tard.

- Une première définition possible et partielle de la classe
Forme, seuls les éléments pertinents pour le cours sont montrés. - Bjarne Stroustrup (et le standard) utilise les termes classe de base et classes dérivées plutôt que super-classe et sous-classes.
- Le cercle a besoin de connaître son centre pour se dessiner. Il serait bien sûr possible de mettre un getter public dans la classe
Forme, mais cette solution n'est pas toujours souhaitable. Le niveauprotecteddonne accès aux membres correspondant aux sous-classes.
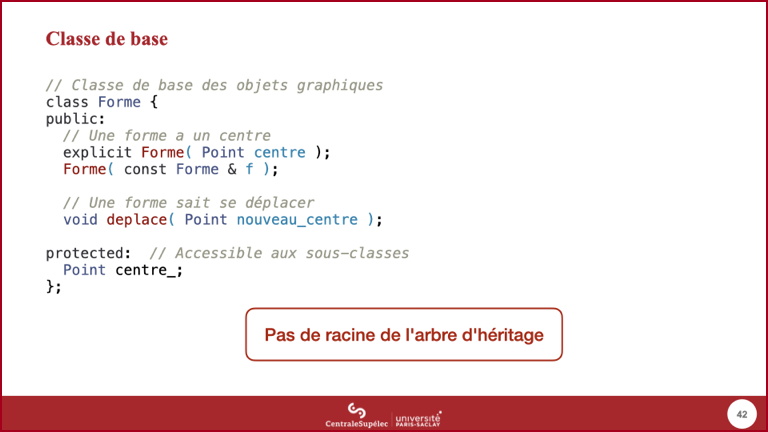
- À noter que, contrairement à la majorité des autres langages orientés objets, il n'y a pas une racine unique de l'arbre d'héritage (« Pay only for what you use »). Ainsi,
Formen'a pas de super-classe.
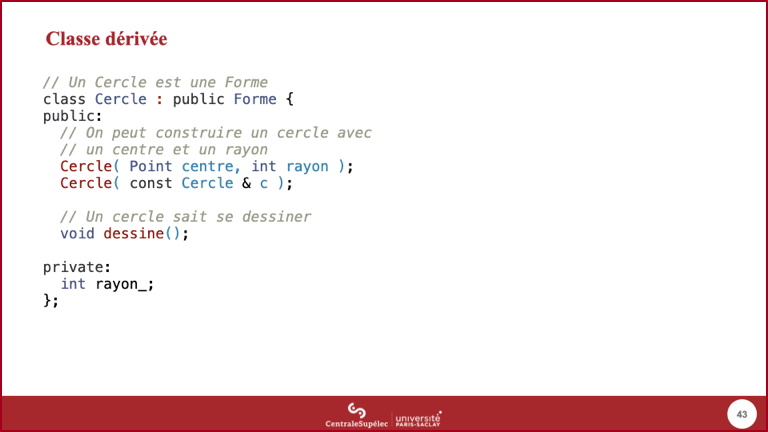
- L'héritage ne s'exprime pas avec un nouveau mot clef, mais par cette syntaxe utilisant le
:. publicest bien le mot clef correspondant à la protection : ici, il signifie que tout le monde sait queCercleest une sous-classe deForme. Ce point sera repris juste après.- À noter que C++ supporte l'héritage multiple (
Cerclepourrait avoir plusieurs classes de base, séparées par des,au niveau syntaxique) : cet aspect ne sera pas abordé dans ce cours.

- Un cercle est une forme, donc il est possible d'affecter dans une variable de type
Formeune expression de typeCercle; par contre, seule la partieFormedeCercle(ici, le centre) est recopié, donc il y a perte d'information. Il n'est par contre pas possible d'affecter dans une variable de typeCercleune expression de typeForme. - Il est aussi possible d'affecter dans une variable de type
Forme *une expression de typeCercle *:pfne verra que la partieFormedu cercle, mais il n'y a pas dans ce cas de perte d'information : le cercle pointé parpfcontinue d'avoir un rayon, même si celui-ci n'est pas vu parpf. On peut aussi considérer qu'il existe une conversion implicite deCercle *versForme *. - On dit que
pfest une variable polymorphique : elle peut pointer sur une instance deForme, deCercleou deRectangle. - La conversion implicite de
Forme *versCercle *est interdite : peut-être qu'il y a effectivement une instance deCerclederrièrepf, mais peut-être que c'est une instance deRectangle. Il faut donc passer par une conversion explicite. - La conversion explicite avec
static_castse fait sans vérification : le développeur impose au compilateur d'accepter cette conversion. Une version avec vérification sera vue ultérieurement. - Une référence sur valeur gauche est aussi une variable polymorphique :
rfest un autre nom de (la partieFormede)c. - Qui peut écrire
pf = pc? ceux qui savent qu'unCercleest uneForme. Donc tout le monde avec un héritage public. Et seules les méthodes deCercleavec un héritage privé. - L'héritage privé conserve l'héritage structurel, mais se traduit par une perte de l'héritage comportemental : il est très rarement utilisé. Et l'héritage protégé encore moins.
- Attention : par défaut (en l'absence d'indication du niveau de protection de l'héritage),
classimpliquera un héritage privé, alors questructimpliquera un héritage public.


- Il est possible dans une sous-classe de redéfinir une méthode de la super-classe : elle sera alors utilisée à la place de cette dernière quand l'objet récepteur est une instance de la sous-classe.
- Cette redéfinition peut, ou pas, appeler la méthode redéfinie de la super-classe ; en C++, on utilise pour cela l'opérateur de spécification de contexte (pour éviter une récursion infinie).
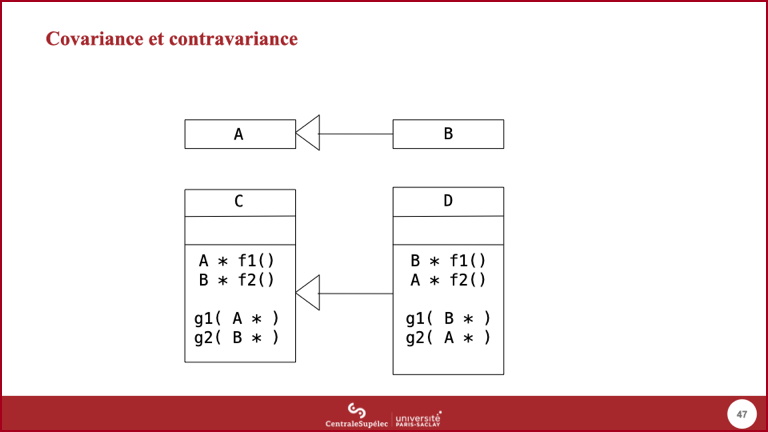
- Covariance : qui varie dans le même sens, contravariance : qui varie dans le sens contraire.
f1()est covariante sur le type de retour dansD: en effet,DspécialiseC, et le type de retour def1()dansDspécialise le type de retour def1()dansC.- À l'opposé,
f2()est contravariante sur le type de retour dansD. - De même,
g1()est covariante sur le type de l'argument dansD,g2()est contravariante. - La question : indépendamment du langage de programmation utilisé, est-ce que la redéfinition de
f1()dansDest valide par rapport à celle dansC? Mêmes questions pourf2(),g1(),g2()? - En général, les langages orientés objets supportent la covariance sur le type de retour, mais pas la contravariance sur le type des arguments :
D::g2( A * )n'est pas une redéfinition deC::g2( B * ), mais une autre méthode avec une signature différente.

- Toute instance est initialisée par l'un des constructeurs de la classe, que ce soit un constructeur généré automatiquement ou un constructeur explicite. Quand une instance de
Cercleest construite, sa partieFormedoit être initialisée par l'un des constructeurs deForme. Formen'a pas de constructeur par défaut (puisqu'un constructeur prenant unPointen argument existe), donc tout constructeur deCercledoit appeler explicitement l'un des deux constructeurs deForme, et donc passer un argument.- La syntaxe pour passer l'argument est identique à celle permettant d'initialiser les attributs, le nom de la super-classe remplace le nom de l'attribut.
- Le code du constructeur de la super-classe est exécuté avant celui de la sous-classe. En sens inverse, le code du destructeur de la super-classe est exécuté après le code de celui de la sous-classe.
- L'appel du destructeur de la super-classe est exécuté automatiquement (la problématique du passage d'argument n'existe pas), et ne peut pas être contourné.



- Ce fichier dans le dépôt Git montre la version actuelle des classes
FormeetCercle.

- On a vu qu'il n'est pas possible d'appeler la méthode
dessine()sur une variable de typeForme *même si l'objet réel pointé par cette variable est une instance deCercle, donc avec une méthodedessine(). - En effet, en C++ (comme en Java ou C# - langages compilés - et contrairement à Python ou JavaScript - langages interprétés), l'existence de la méthode appelée est vérifié à la compilation.
- Il est donc nécessaire de définir une méthode
dessine()dans la classeForme, même si une forme ne sait pas se dessiner.

- Cette modification ne permet pas d'obtenir le comportement souhaité : en effet, si le compilateur ne signale plus d'erreur, la méthode
dessine()exécutée est celle de la classeFormemême si l'objet réel est une instance deCercle. Cet aspect est spécifique à C++ ; Java et C#, par exemple, se comportent correctement après l'ajout de cette méthode. - La raison en est encore « Pay only for what you use » : pour connaître le type réel de l'objet pointé, et donc exécuter la bonne méthode, il y a obligatoirement un coût à l'exécution, coût qui ne peut pas être imposé à tout le monde.
- Le mot clef
virtualpermet d'obtenir le comportement souhaité, à savoir que la méthode exécutée dépend du type de l'objet à l'exécution (liaison dynamique) et non pas du type de l'objet à la compilation (liaison statique). - Le terme de méthode virtuelle est utilisé à cause du choix du mot clef. Ce comportement de liaison dynamique sera appliqué à toute les redéfinitions de cette méthode sans avoir besoin d'utiliser à nouveau le mot clef
virtual. - Il est important de noter que le destructeur de
Formedoit être virtuel (et les destructeurs des sous-classes le deviennent automatiquement alors) : si une instance deCercleallouée dynamiquement est détruite via un pointeur de typeForme *, il faut que le destructeur deCerclesoit exécuté.


- La redéfinition d'une méthode virtuelle dans une sous-classe doit être conforme à la signature de la version de la super-classe. Une modification de cette signature dans la super-classe ne se traduira pas par défaut par un signalement d'erreur par le compilateur, mais le comportement obtenu ne sera plus correct.
- Le mot clef
overridepermet d'activer cette vérification par le compilateur : la méthode qualifiée ainsi doit être une redéfinition d'une méthode virtuelle de la super-classe.

- Un cercle ou un rectangle sait se dessiner, mais pas une forme. Pourtant, cette méthode doit être déclarée dans
Forme: on peut indiquer que cette méthodedessine()deFormeest abstraite avec cette syntaxe, certes bizarre, mais qui évite l'introduction d'un nouveau mot clef. - Toute classe qui a au moins une méthode abstraite est abstraite, c'est-à-dire qu'il n'est pas possible de créer des instances directes d'une telle classe. Ceci permet aussi d'imposer un certain comportement aux sous-classes qui doivent redéfinir cette méthode pour être concrètes.

- L'héritage pose plus de problèmes de conception que de problèmes de codage : quand est-il pertinent de l'utiliser ?
- Le principe de substitution de Liskov, l'un des 5 principes de bonne conception connus sous l'acronyme SOLID, donne un élément de réponse même s'il s'applique au sous-typage qui n'est pas strictement la même chose que la spécialisation de classes.
- L'auteur de cette formalisation des 5 principes est Uncle Bob.
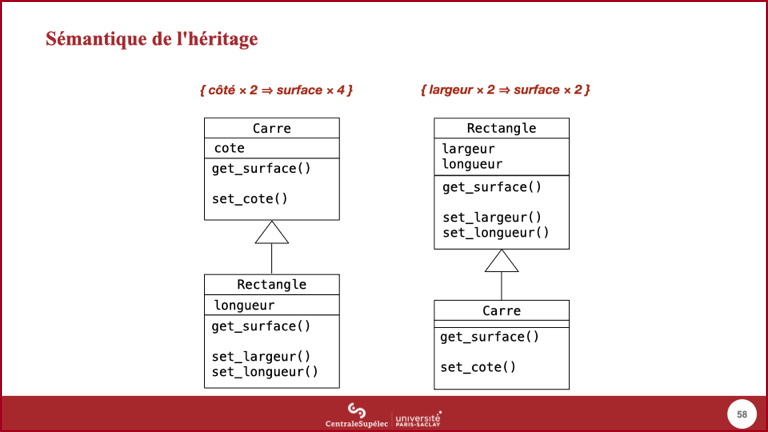
- Pour revenir à la question « pourquoi pas des ellipses et des rectangles, ou des cercles et des carrés », examinons deux idées possibles d'ajout d'une classe
Carreà notre mini-domaine. - La première idée est basée sur l'héritage de structure : un carré a une dimension, un rectangle en a deux, donc
Rectangleest une sous-classe deCarre, en réutilisant son attributcotepour mémoriser la largeur et en ajoutant un attribut longueur. - La deuxième idée est basée sur la vision ensembliste de l'héritage : l'ensemble des carrés est inclus dans l'ensemble des rectangles, tout comme l'ensemble des rectangles est inclus dans l'ensemble des formes, donc
Carreest une sous-classe deRectangle. - Pour formaliser le comportement des objets (et donc expliciter ce que veut dire « pas de changement en cas de substitution », une approche se base sur la notion d'invariant : une propriété d'un objet qui est toujours vraie.
- On voit dans les deux cas qu'un invariant de la super-classe ne s'applique pas à la sous-classe.

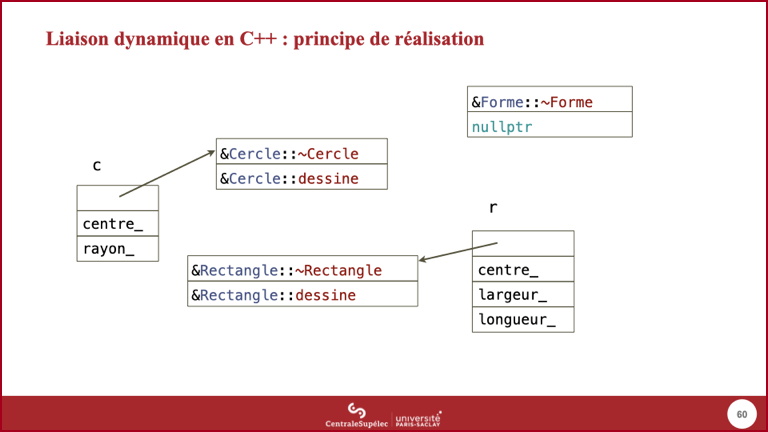
- Il est légitime de se poser la question du surcoût imposé par la présence de fonctions virtuelles.
- Ce schéma est une version simplifiée du principe de mise en œuvre, en particulier car il ne tient pas compte de l'héritage multiple. Mais les ordres de grandeur des surcoûts sont corrects.
- Pour toute classe ayant au moins une fonction virtuelle, le compilateur crée une, et une seule, table des fonctions virtuelles qui contient les adresses des méthodes en question selon un ordre connu du compilateur. Ce surcoût en espace est donc constant quel que soit le nombre d'objets.
- Chaque instance de l'une de ces classes possède dans sa représentation un pointeur vers la table de sa classe. Le surcoût en espace peut être considéré comme important dans la représentation par exemple d'un complexe dans un contexte de calcul scientifique (sa taille est augmentée de 50% avec des
double, ou 100% avec desfloat), mais négligeable dans des objets plus métiers. - L'appel d'une méthode virtuelle implique donc une indirection à travers la table pointée par l'objet : là aussi, ce surcoût en temps peut être considéré comme significatif ou pas selon le contexte.
- Dans tous les cas, toute solution alternative (classiquement, un attribut
typedans l'objet) sera moins performante.


- Ce fichier dans le dépôt Git montre la version finale des classes
FormeetCercle.

- Ce pointeur sur la table des fonctions virtuelles permet de tester le type des objets à l'exécution.
- Cette possibilité est utilisée pour l'identification dynamique de type :
dynamic_castretourne un pointeur valide si l'objet pointé est du type demandé,nullptrsinon.

- Comme une référence sur valeur gauche ne peut pas être invalide, une exception est émise à la place.

© 2025 CentraleSupélec