

Table of contents
SQLite
SQLite is a C-language library that implements a small, fast, self-contained SQL database engine.
In order to use SQLite we will use DB Browser for SQLite that you should already have installed if you followed the instructions that we sent by email before the beginning of the course. If you didn't install it, go to the following address SQLite Download page.
On macOS, the first time you launch DB Browser for SQLite, the system will tell you that this application cannot be opened (this security measure is designed to protect you from malicious software). If you have downloaded it from the given link, we know that this application is safe. To enable its use, choose Show in Finder, then use the secondary click on the icon, then choose Open, and Open again in the displayed dialog.
The database
In this lab we will use a simplified version of the Sakila database. The database contains fictitious data on a DVD rental store, featuring entities such as films, actors, film-actor relationships, and a central inventory table that connects films, stores, and rentals. Sakila is composed of 16 tables; download it using this link, and use the Open database command of DB Browser for SQLite to load it.
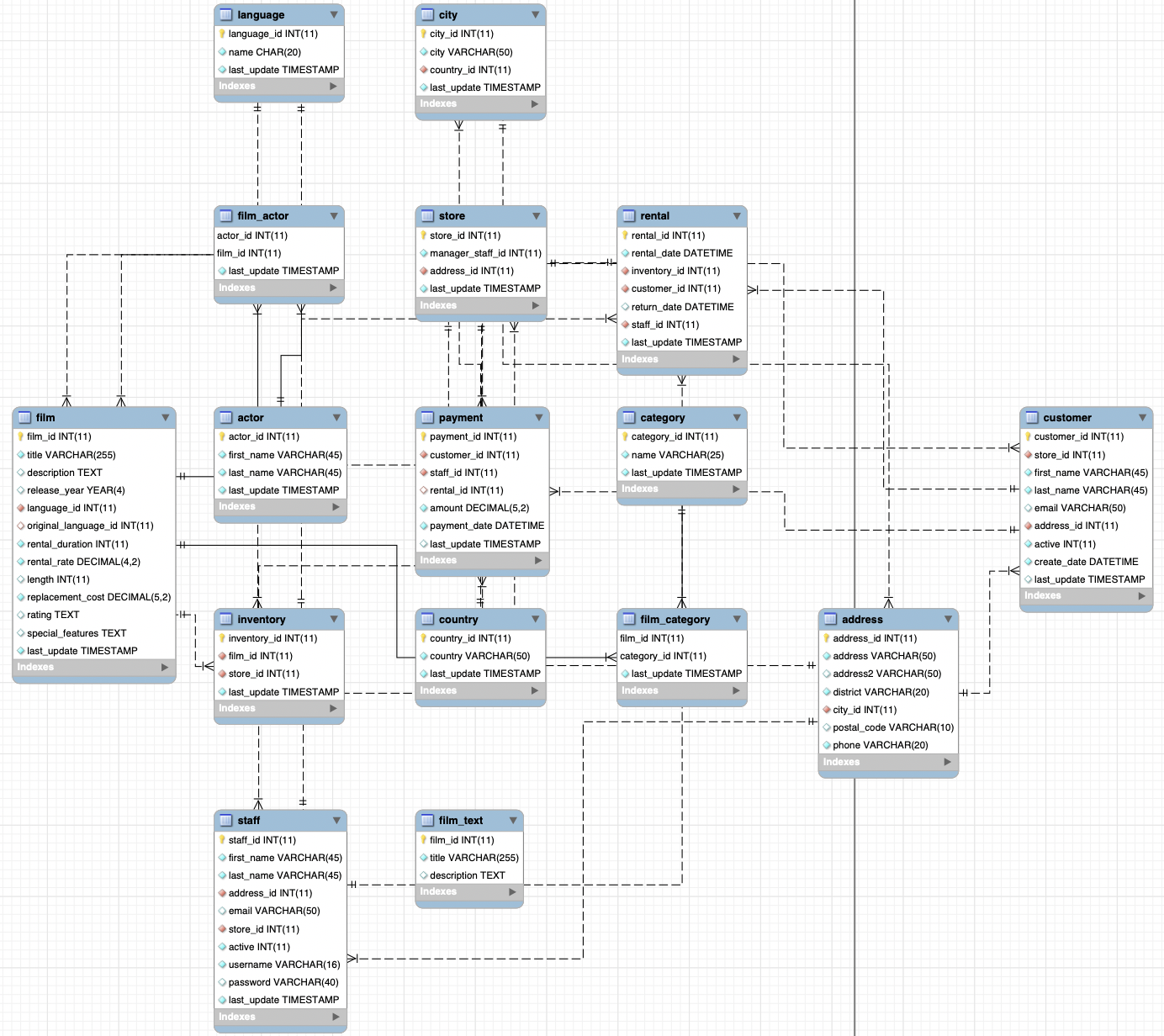
The schema of Sakila database
SCHEMA CREATION
As first step you're asked to enrich the Sakila schema with new tables. We'll use SQL; a reference guide is available at the following address (you can use this reference if you have any doubt during the definition of your queries): https://www.w3schools.com/sql/default.asp (the specific version of SQLite is described here).
Now focus on the structure of the database by learning the instructions for creating and deleting the elements characterizing a relational database (i.e., tables, columns, ...).
The SQL instruction that deletes a table is the DROP TABLE statement:
DROP TABLE IF EXISTS tableName;
while the instruction that creates a table is the CREATE TABLE statement, which has the following syntax:
CREATE TABLE IF NOT EXISTS tableName (
column1Name dataType columnConstraint DEFAULT defaultValue,
column2Name dataType columnConstraint DEFAULT defaultValue,
…
);
Here's a short description of the components of this statement:
CREATE TABLE IF NOT EXISTSgenerates a new table with the nametableNameif and only if it does not exists yet.- The list of columns in the table is given between parentheses.
Columns are declared through the following elements:
columnName, name of the columns (mandatory).dataType, type of the values in the column (mandatory).columnConstraint, list of integrity constraints on the column values (optional).
The following tables lists the types that you can assign a column.
INTEGER, BOOLEAN | The integer datatype can store whole integer values. In some implementations, the boolean value is just represented as an integer value of just 0 or 1. |
FLOAT, DOUBLE, REAL | The floating-point datatypes can store more precise numerical data like measurements or fractional values. Different types can be used depending on the floating-point precision required for that value. |
CHAR(num_chars), VARCHAR(num_chars), TEXT | The text-based datatypes can store strings and text in all sorts of locales. The distinction between the various types generally amounts to the underlying efficiency of the database when working with these columns. |
Both the CHAR and VARCHAR (variable character) types are specified with the maximum number of characters that they can store (longer values may be truncated), so can be more efficient to store and query with big tables.
Each column can have additional constraints on it, which limits what values can be inserted into that column. This is not a comprehensive list, but will show a few common constraints that you might find useful in the exercises.
NOT NULL | Ensures that a column cannot have a NULL value (remember that NULL indicates the absence of a value) |
UNIQUE | Ensures that all values in a column are different (you can't have two rows with the same value in the column) |
PRIMARY KEY | A combination of a NOT NULL and UNIQUE. Uniquely identifies each row in a table. |
FOREIGN KEY | Ensures that each value in a column or a set of columns is found in a column or set of columns in another table (referential integrity constraint). |
DEFAULT | Sets a default value for a column when no value is specified. |
AUTOINCREMENT | For integer values, this means that the value is automatically filled in and incremented with each row insertion. |
In DB Browser for SQLite, select the Execute SQL tab, copy-paste the following statement and execute it using the ► button.
CREATE TABLE film_director (
director_ID varchar(32),
film_ID smallint(5),
PRIMARY KEY (director_ID,film_ID),
FOREIGN KEY (director_ID) REFERENCES director(director_ID)
FOREIGN KEY (film_ID) REFERENCES film(film_ID)
);
The query is executed by DB Browser for SQLite and no errors are shown but there is a conceptual problem. Which one? Hint: do all foreign keys reference existing items?
INSERTING DATA
The INSERT INTO statement is used to add one or more rows to a table. You need to specify the target table and, for each row, the list of columns for which you specify a value and the actual values.
INSERT INTO tableName
(column1Name, column2Name, …)
VALUES (value_or_expr_for_column1, value_or_expr_for_column2, …),
(value_or_expr_for_column1, value_or_expr_for_column2, …),
… ;
Execute the following statement:
INSERT INTO director
(Director_ID, First_Name, Last_Name)
VALUES ("1234", "Woody", "Allen"),
("1234", "Nicolas", "Winding");
Explain the error that you get.
Execute the following statement and explain why it returns an error:
INSERT INTO film_director
(Director_ID, Film_ID)
VALUES ("1234", 5);
INSERT INTO director
(Director_ID, First_Name, Last_Name)
VALUES ("1234", "Woody", "Allen");
Provide a correct version of the two statements and execute them.
What happens if you delete all the films (or one of the films) of a director? Would it be possible? What do you have to check before executing this operation?
QUERYING DATA
A SELECT statement is used to read data from the database. Here, columnName1, columnName2, ... are the column names of the table that you want to select data from.
SELECT columnName1, columnName2, ... FROM tableName;
Note that the result of a SELECT statement is a table. If you want to select all columns, use the following syntax:
SELECT * FROM tableName;
The SELECT DISTINCT statement is used to return only distinct (different) values.
If we want to only read a fixed number of rows in the result, we can use the LIMIT clause. The following
only returns the first five rows in table actor.
SELECT * FROM actor LIMIT 5;
The WHERE clause is used to get a subset of rows satisfying a given condition.
SELECT columnName1, columnName2, ... FROM tableName WHERE condition LIMIT 5;
The following operators can be used in the WHERE clause:
| =, !=, < <=, >, >= | Standard numerical operators columnName != value |
BETWEEN x AND y | TRUE if the operand is within the range of comparisons (inclusive) |
NOT BETWEEN x AND y | TRUE if the operand IS NOT within the range of comparisons (inclusive) |
IN ( ... ) | TRUE if the operand is equal to one of a list of elements (and in general expressions) |
NOT IN ( ...) | TRUE if the operand IS NOT equal to one of a list of elements (and in general expressions) |
If the rows of your results are shown according to a different order do not worry: since we are not specifying any sorting option the visualization of data is random and sometimes is affected by the inserting order (and many other fetching variables that are not studied in this class).
Try to define and execute the following queries:
Show the first and last names of all the actors stored in the table actor.
The expected result:
| First_Name | Last_Name |
|---|---|
| PENELOPE | GUINESS |
| NICK | WAHLBERG |
| ED | CHASE |
| .. | ... |
- Find the ID number, first name, and last name of an actor, of whom you know only the first name, "WOODY".
Pay attention, the values are case sensitive: Woody is different from WOODY.
The expected result:
| Actor_ID | First_Name | Last_Name |
|---|---|---|
| 28 | WOODY | HOFFMAN |
| 82 | WOODY | JOLIE |
- Display the country_id and country columns of the following countries: {Italy, France, China}
The expected result:
| Country_ID | Country |
|---|---|
| 23 | China |
| 34 | France |
| 49 | Italy |
Up to now, you have been working with a single table, but as we have seen data is spread across different tables following the normalization criteria. Database normalization is useful because it minimizes unnecessary redundancies.
A JOIN operation is used to combine rows coming from two tables, based on common values of specified columns. Usually, the foreign key is used to join two tables, although this might not be always the case,
SELECT column_name(s) FROM tableName1 JOIN tableName2 ON tableName1.column_name = tableName2.column_name;
Sometimes it is useful to give tables or columns an alias while writing a query.
The AS keyword serves this purpose.
SELECT column_name(s) FROM tableName1 AS t1 JOIN tableName2 AS t2 ON t1.column_name = t2.column_name;
Note that aliases are only visible within the query: the tables in the database maintain the original name.
If you intend to join two tables on the common values of columns that share the same name in both tables, you can use the following syntax:
SELECT column_name(s) FROM tableName1 AS t1 JOIN tableName2 AS t2 USING (column_name);
Get the title and the name of the language of each film.
The expected result:
| Title | Name |
|---|---|
| ACADEMY DINOSAUR | English |
| ACE GOLDFINGER | English |
| ADAPTATION HOLES | English |
| AFFAIR PREJUDICE | English |
| AFRICAN EGG | English |
| AGENT TRUMAN | English |
| ... | ... |
Get the first and last name of the manager of the store identified by the code '2'.
The expected result:
| First_Name | Last_Name |
|---|---|
| Jon | Stephens |
It is also possible give tables an alias without the keyword AS, we will see it in more complex queries.
SELECT column_name(s) FROM tableName1 t1 JOIN tableName2 t2 ON t1.column_name = t2.column_name;
Write a query that lists the first and last names of all the actors who played a role in the movie 'ANGELS LIFE';
The expected result:
| First_Name | Last_Name |
|---|---|
| PENELOPE | GUINESS |
| JENNIFER | DAVIS |
| GRACE | MOSTEL |
| JULIA | BARRYMORE |
| CHRISTOPHER | BERRY |
| ED | MANSFIELD |
| ... | ... |
SQL also supports the use of aggregate expressions (or functions) to summarize information on a group of rows: COUNT, MAX, MIN, SUM, AVG. In addition to aggregating across all the rows, you can apply the aggregate functions to individual groups of data. The GROUP BY statement is often used with aggregate functions to group the result-set by one or more columns. SQL also provides a way to sort your results by a given column in ascending or descending order using the ORDER BY clause.
SELECT AGG_FUNC(column_or_expression) AS aggregate_alias, … FROM tableName WHERE constraint_expression GROUP BY column;
The following query returns the number of customers of each store:
SELECT COUNT(Customer_ID), store_id FROM Customer GROUP BY store_id;
Write a query that returns the number of films in which each actor played a role.
The expected result (the order in which you see the result can be different from the one we provide):
| First_Name | Last_Name | films |
|---|---|---|
| PENELOPE | GUINESS | 19 |
| NICK | WAHLBERG | 25 |
| ED | CHASE | 22 |
| JENNIFER | DAVIS | 22 |
| JOHNNY | LOLLOBRIGIDA | 29 |
| BETTE | NICHOLSON | 20 |
| GRACE | MOSTEL | 30 |
| MATTHEW | JOHANSSON | 20 |
| ... | ... | ... |
Write a query that returns the film categories in which there are between 25 and 55 films;
The expected result:
| Category | FilmsCount |
|---|---|
| Music | 51 |
Write a query that returns the first and last name of one of the actors that played in the most films; for this actor, return also the number of movies in which s/he played.
The expected result:
| First_Name | Last_Name | films |
|---|---|---|
| Gina | Degeneres | 42 |
Hint: think about using LIMIT and ORDER BY.
Sometimes you need to use more complex join operations. When joining two tables, you have the following possibilities:
- You want to return only the rows that have a match in both tables. You use then an
INNER JOIN(or simply aJOIN). This is the operation that we've been using so far. - You want to return all the rows from the left table, even if they don't match any in the right table. You use then a
LEFT JOIN. - You want to return all the rows from the right table, even if they don't match any in the left table. You use then a
RIGHT JOIN. - You want to return all the rows from both the left table and the right table, including those that have no match in either direction. You use then a
FULL OUTER JOIN(orFULL JOIN).
Write a query that lists the IDs of all the customers who have rented more than five family movies and the number of movies they rented;
The expected result:
| customer_id | cnt |
|---|---|
| 410 | 6 |
| 213 | 6 |
| 439 | 6 |
| 343 | 6 |
| 526 | 7 |
| 550 | 6 |
| ... | ... |
Write a query that returns the names of all the actors that played a role in the most films. For example, if the maximum number of films per actor is 50 and there are three actors who played in 50 movies, you need to return all of them.
You need to add some data to verify the correctness of your query. Just execute the two following INSERT operations one by one"
INSERT INTO film(film_id, title, language_id) values (10001, "Immaginary dummy film", 1); INSERT INTO film_actor(actor_id,film_id) values (102,10001);
The expected result:
| first_name |
|---|
| WALTER |
| GINA |
HINT: to write the query you might need to use nested subqueries. Remember that a subquery is a SELECT statement that is nested within another SELECT statement.
Write a query that returns the names of the films that have been rented zero or one time (use a LEFT JOIN).
To verify the correctness of the query, add some data to the database by executing the following statement:
INSERT into inventory values (4582,10001,2,'2019-03-15 07:09:17');
The expected result:
| Film_ID |
|---|
| 10001 |