Table des matières
TD n°1
Exercice 1, question 1Exercice 1
Exercice 1, question 2
Un graphe contient un cycle ayant un nombre impair d'arêtes ssi il existe une arête dont les deux extrémités ont la même profondeur.
On remarque tout d'abord que les profondeurs de deux sommets adjacents d'un graphe diffèrent au maximum de 1. En effet, elles peuvent être égales si les deux sommets sont atteints par des chemins de longueurs égales, mais elles ne peuvent différer de plus de 1 puisque si c'était le cas, en prenant P la profondeur la plus petite, on atteindrait l'autre sommet en P+1 arêtes en suivant l'arête qui relie les deux sommets.
Preuve :
=> on fait la preuve en prenant la contraposée : si toutes les arêtes
relient des sommets de profondeurs différentes, le graphe ne contient
pas de cycle de longueur impaires. En effet, si toutes les arêtes
relient des sommets de profondeurs différentes, ces profondeurs
diffèrent toutes de 1. En parcourant le cycle, on alterne donc entre des
sommets de profondeur paire et des sommets de profondeur impaire. Pour
revenir au sommet de départ (et donc à la même parité pour sa
profondeur) dans le parcours du cycle, il faut donc suivre un nombre
pair d'arêtes. il ne peut donc pas y avoir de cycle de longueur impaire.
<= s'il existe une arête reliant deux sommets x et y de même profondeur, on recherche l'ancêtre commun r à ces deux sommets (au pire, c'est la racine). Les chemins de r à x et de r à y ont la même longueur L, donc la somme de leurs longueurs, 2L est paire. En ajoutant l'arête qui relie x à y, on obtient un cycle de longueur 2L+1, qui est bien impaire.
Exercice 1, question 3
Exercice 1, question 4
Dans un graphe biparti, il ne peut pas exister de cycle ayant un nombre impair d'arêtes.
En effet, toutes les arêtes d'un graphe biparti relient un sommet de V1 à un sommet de V2. Pour fermer un cycle, il faut donc que ce cycle fasse un nombre entier d'aller-retours entre V1 et V2, sa longueur est donc nécessairement paire.
Réciproquement, si un graphe ne contient pas de cycle ayant un nombre impair d'arêtes, il est biparti. En effet, toute arête relie alors des sommets de profondeurs qui diffèrent exactement de 1. Toute arête relie donc un sommet de profondeur paire à un sommet de profondeur impaire. En choisissant pour V1 le sous-ensemble des sommets de profondeur paire, et pour V2 le sous-ensemble des sommets de profondeur impaire, on obtient une partition des sommets en deux sous-ensembles, telle que toute arête relie des sommets appartenant à des sous-ensembles différents.
Exercice 1, question 5
Exercice 2, question 1Exercice 1
Un graphe est 2-coloriable ssi il est biparti
En effet, si le graphe est 2-coloriable, on prend pour V1 les sommets de la première couleur, et pour V2 ceux de la deuxième couleur. On a alors une partition des sommets du graphe, et toutes les arêtes relient un sommet de V1 à un sommet de V2 puisque deux sommets adjacents n'ont pas la même couleur.
Réciproquement, si un graphe est biparti, on colore d'une couleur les sommets de V1 et de l'autre couleur les sommets de V2 et on obtient un 2-coloriage du graphe.
Exercice 2, question 2
Exercice 2, question 3
L'algorithme est correct car :
- quand il rend True, il a parcouru tous les sommets du graphe en donnant une couleur différente aux sommets adjacents, ou en vérifiant que les couleurs sont différentes quand un voisin est déjà coloré.
- quand il rend False, il a trouvé deux sommets adjacents de même couleur, c'est-à-dire dont les profondeurs ont la même parité. La somme de ces parités est donc paire (car impair + impair -> pair, et pair + pair -> pair). En fermant ces deux chemins avec l'arête qui relie ces sommets, ont obtient donc un cycle de longueur impaire, ce qui signifie que le graphe n'est pas biparti et donc pas 2-coloriable.
Exercice 3
Un graphe orienté sans circuit contient au moins un sommet qui n'a pas d'arc entrant.
On démontre la contraposée : si tous les sommets ont au moins un arc entrant, le graphe contient un cycle.
En effet, prenons un sommet au hasard. Il possède un arc entrant que nous suivons pour arriver à un autre sommet. Ce sommet a également un arc entrant que nous suivons etc. On obtient donc une suite infinie de sommets en remontant les arcs entrant. Or le nombre de sommets du graphe est fini, et cette suite infinie doit donc repasser plusieurs fois par le même sommet. Il y a donc un circuit dans le graphe.
TD n°2
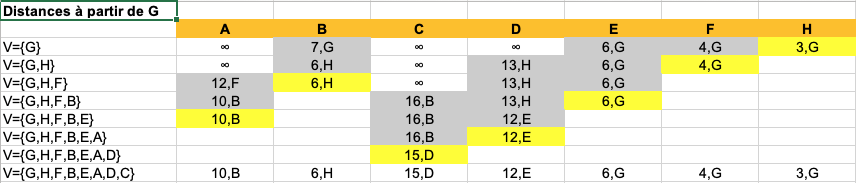
Dessin des graphes pour les différentes questions
TD n°3
Dessin des graphes pour les différentes questions
TD n°4
Dessins au tableau pour les différentes questions
TD n°6
Dessins au tableau pour les différentes questions
TD n°7
Dessins au tableau pour les différentes questions
TD pratique n°8