Introduction
XML vient du besoin d'échanger des données entre acteurs :
- Données bancaires
- Données de remboursement de santé
- Description d'une recherche d'itinéraire dans Google Maps
- La réponse associée: description d'un itinéraire
- ...
D'où la nécessité d'un format de structuration universel :
- Permettant de représenter toutes sortes de données structurées (non limitant à un certain type de données)
- Lisible sur tous les systèmes
- Le plus simple possible
Deux formats d'échange sont maintenant standards sur le web:
- XML (1998)
- Généralisation de HTML pour représenter toutes sortes de données et pas seulement des pages web
- « SGML simplifié »
- Texte balisé
- Origine : W3C avec un soutien industriel fort (Microsoft)
- JSON (2006)
- Sous-ensemble de JavaScript (littéraux)
- Origine : développement propriétaire standardisé ensuite
Validation des données
Pour l'interopérabilité, il est essentiel de d'abord s'accorder sur un format de donnée, et de s'assurer que les documents échangés en ligne satisfassent effectivement la spécification. En XML, on peut faire énormément:
- Espaces de noms: permettent d'imbriquer différents langages XML suivant des spécifications différentes
- Nombreux langages de descriptions de format pour un espace de nom donné:
- Description de la structure
- Mais aussi description du type des données textuelles: date, nombre, booléen,...
- On peut nommer: le vénérable format DTD, le plus récent système des schémas XML, permettant plus, mais aussi Relax NG, un format moderne et très souple de description d'arbre...
À contrario, JSON est beaucoup plus simple: pas de notion d'espace de noms, et pas de méthode de spécification (ou en tout cas pas de standard).
Le format XML est donc recommandé pour des applications requérant l'échange de données entre différents partenaires, tandis que la simplicité de JSON en fait un bon candidat pour le stockage et les échanges en interne dans une application.
XML
Le web a eu un succès phénoménal à son introduction dans les années 1990. L'une des raisons est que HTML est simple: il suffit d'un éditeur de texte pour créer des pages web !
L'idée a donc été de généraliser HTML pour structurer toutes sortes de documents, pas seulement des pages web. Cela a donné naissance à un nouveau méta-langage appelé XML, plus simple que SGML. Standardisé en 1998, le développement d'XML est chapeauté par le consortium W3C (World Wide Web Consortium), avec des soutiens industriels forts, notamment de la part de Microsoft pour son introduction.
Les objectifs d'XML sont les suivants:
- Technologie universelle pour structurer l’information
- Adapté à la diffusion et à l’échange d’information
- Orienté vers la structuration des données
- Indépendant des plates-formes, et des systèmes d’exploitation
- Fondé sur une syntaxe de type « texte balisé » simple qui a fait le succès de HTML
Différences HTML / XML
HTML :
- description d'un document (sur le modèle d'un article imprimé)
- structure : titres (h1 ... h6), paragraphes, listes
- présentation : italiques, gras (au départ ; maintenant en désuétude)
- insertion d'images, vidéos
XML :
- structuration logique de données
- pas de représentation envisagée a priori
Par exemple:
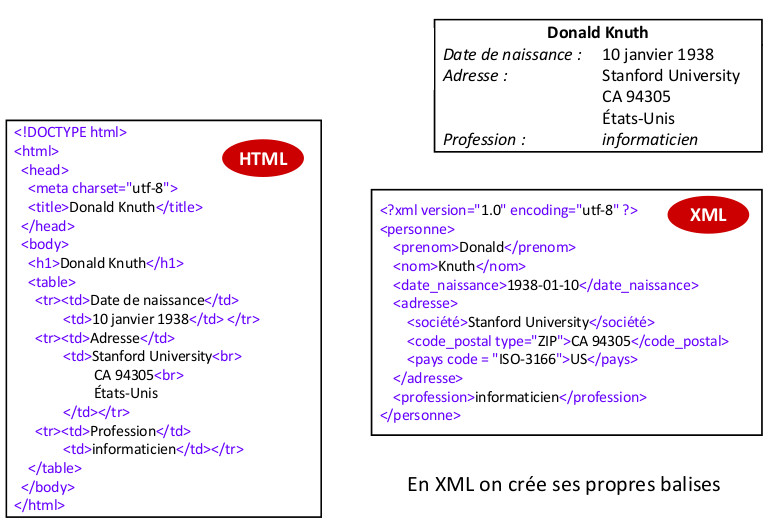
Dualité texte balisé - arbre
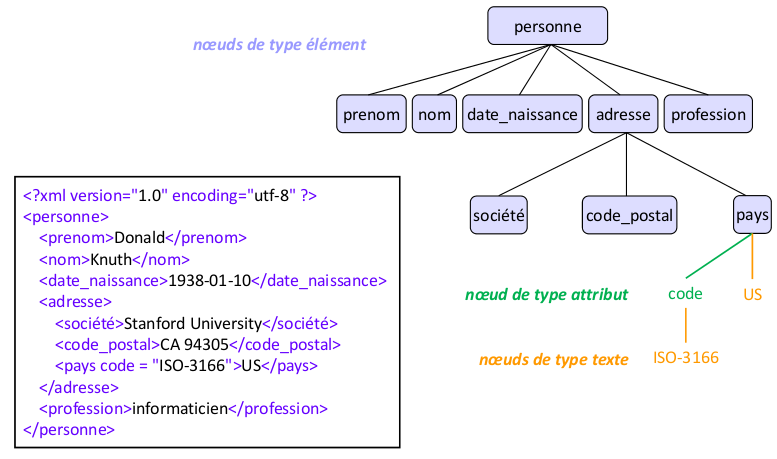
Comme en HTML, un texte XML essentiellement représente un arbre. À la différence de HTML, on peut mettre n'importe quelle balise:
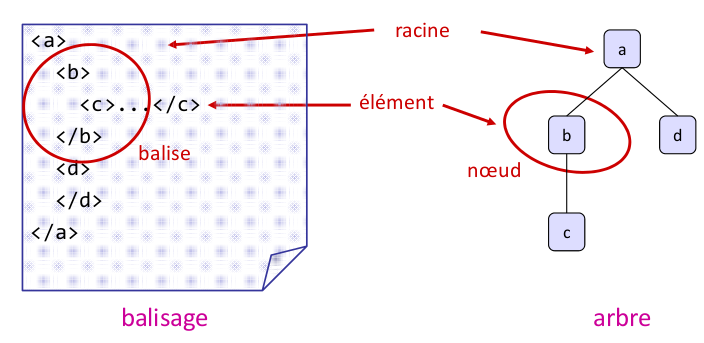
Par exemple, on peut imaginer un format de carte de visite comme suit:
Syntaxe
Les mêmes considérations qu'en HTML s'applique, en particulier concernant l'encodage de caractères et des caractères d'échappement.
Ceci dit, la syntaxe est à la fois plus souple car les balises peuvent être arbitraires et plus riche gràce aux espaces de nom.
Document XML bien formé
Un document XML doit respecter le format de base XML. Il est alors dit bien formé, sinon il est inexploitable. Par exemple, voila la description d'un point géographique en KML (Google Earth):
La bonne formation d'un document XML est essentiel: un parseur XML se
comportera de façon imprévisible en présence d'un document mal
formé. Un exemple d'un document mal formé est:
Vous pouvez mettre ce document dans un fichier malforme.xml puis
essayer de l'ouvrir avec firefox. Vous aurez alors un message
d'erreur.
Si la bonne formation d'un document est une condition sine qua non, elle n'est en général pas suffisante: il faut aussi que l'arbre XML décrit par le document corresponde à ce qui est attendu: Il faut confronter l'arbre à la grammaire souhaitée. Comme dit plus haut, plusieurs langages existent pour cela:
- le vénérable format DTD,
- le plus récent système des schémas XML, permettant plus,
- Relax NG, un format moderne et très souple de description d'arbre.
Les deux premiers sont décrit dans le tuto sur la validation XML.
Prologue XML
Il s'agit de la première ligne. Les symboles @<?xml@ permet de savoir qu'il s'agit d'un document XML. Ensuite:
- indiquer la version : 1.0 ou 1.1 (différences négligeables)
- préciser le codage de caractères utilisé. Par défaut il s'agit du jeu de caractères international Unicode, avec le codage UTF-8.
On peut donc omettre l'encodage: ou indiquer qu'on veut vraiment de l'UTF-8: ou encore indiquer un autre encodage:
Les balises
Comme en HTML, une balise a la forme suivante: Si la balise n'a pas de fils, on peut faire mais aussi (notez le "/" à la fin). On la balise peut bien sûr avoir des attributs:
Format des balises et des attributs
Ce sont les identifiants. Les règles de nommage des identifiants sont les suivants:
- un caractère ou plus
- caractères autorisés :
- chiffres
- lettres (tous alphabets)
- _ (souligné, underscore)
- - (trait d'union, hyphen)
- . (point, dot)
- sauf 1er caractère : seulement lettres ou _ (souligné)
- jamais d'espaces, jamais d'autres caractères de ponctuation !
- et surtout pas de ":", ils servent pour les espaces de nom.
- Enfin, la capitalisation est importante:
<a>et<A>sont distincts.
Espaces de noms
Objectif: Distinguer les éléments et attributs issus de divers vocabulaires et pouvant partager le même nom. Par exemple, <set>
- Dans MathML : ensemble mathématique.
- Dans SVG : fixe la valeur d'un attribut à une durée de temps précise
Le deuxième objectif est de grouper tous les éléments XML appartenant à une même application XML pour que les logiciels puissent les reconnaître facilement.
L'espace de nom est associé à un élément ou un attribut à l'aide d'un préfixe:
prefix:elementprefix:attribut
Le préfixe est associé à un espace de nom qui est sous la forme d'une URI (en général une adresse internet qui pointe sur la définition). On l'appelle nom qualifié. L'association se fait avec La portée de la déclaration est l'élément où elle apparait et tous ces descendants.
Quelques exemples de noms qualifiés classiques:
| XHTML | http://www.w3.org/1999/xhtml |
| MathML | http://www.w3.org/1998/Math/MathML |
| SVG | http://www.w3.org/2000/svg |
| RDF | http://www.w3.org/TR/REC-rdf-syntax# |
| Dublin Core | http://purl.org/dc |
Les espaces RDF et Dublin Core servent à placer des méta-données dans un document XML. Par exemple:
Quelques règles:
- Les éléments et attributs sans préfixe (comme
about) ne sont dans aucun espace de nom, même si ils appartiennent à un élément avec espace de nom. - Certains préfixes sont canoniques, comme
dc,rdf,svg.
On peut aussi utiliser xmlns seul. Par exemple: Tous les éléments descendants de <svg> seront dans l'espace de nom, mais les attributs : width, height sont sans espace de nom (donc il faut un préfixe si on veut imposer un espace de nom à un préfixe).
Vous pourriez vous demander quel est l'intéret de mettre des espaces de nom spécifiques aux attributs. Cela permet d'augmenter un langage existant avec de nouvelle fonctionnalités. Par exemple, on peut intégrer la technologie XLink dans un document XHTML. Donc on a un document avec comme espace de nom XHTML qui contient parfois des attributs XLink pour donner des fonctionalités supplémentaires aux balises. Par exemple, ici on a du SVG, du XHTML et du XLink (uniquement sur les attributs):
Format du contenu
Comme pour HTML, presque tous les caractères sont autorisés entre les balises et dans les valeurs des attributs, sauf
- Pas de " dans la valeur d'un attribut délimitée par "
- Pas de ' dans la valeur d'un attribut délimitée par '
- < et & interdits partout
Comme en HTML, on peut échapper un caractère avec "&codecar;". Le code du caractère est soit son numéro de caractère unicode, soit un caractère spécial:
- ' pour '
- > pour >
- < pour <
- " pour "
- & pour &
Et on peut placer du texte arbitraire dans les sections CDATA:
Interfaces de programmation
Deux API permettent de lire et écrire des documents XML depuis un programme :
- DOM (Document Object Model), cf. le tuto en question
- Vision arborescente
- Parcours de l'arbre XML
- Nativement accessible depuis JavaScript dans les navigateurs
- SAX (Simple API for XML)
- Modèle événementiel
- Vision « document = suite de balises»
- Particulièrement utile dans le cadre d'un fichier XML très large dans lequel on recherche une petite information.
Ces deux API sont disponibles dans tous les langages
XML en javascript
L'interface DOM est standardisée sur tous les navigateurs. Et la bibliothèque Jquery fonctionne aussi bien sur un arbre XML que sur du HTML. C'est ce qui est recommandé en général et pour ce cours en particulier.
Le modèle SAX par contre n'est pas standardisé en JavaScript (car peu utilisé dans le contexte d'un navigateur). Si on veut vraiment, ceci dit, Mozilla a par exemple sa propre librairie.
JSON
JSON est l'initiale de"JavaScript Object Notation". Le concept: une donnée structurée est composée de tables d'association et de tableaux imbriqués. Par contre, par rapport à XML il n'y a pas de notion d'espace de noms. C'est un modèle plus souple, mais dans lequel il n'y a pas de système de validation standardisé comme pour le XML.
Un exemple exemple de fichier JSON: Avantages:
- Sous-ensemble de JavaScript
- Indépendant du langage
- Bibliothèques JSON existent dans tout langage
JSON avec javascript
À l'origine, l'idée initiale est que JavaScript dispose d'une fonction eval() qui exécute du code JavaScript contenu dans une chaîne. On peut donc en théorie utiliser eval() pour analyser du JSON :
Problème : énorme faille de sécurité ! Et si le soi-disant JSON contient du code malicieux ?
Ne jamais utiliser eval(), utiliser la bibliothèque JSON
La bibliothèque JSON
Cette bibliothèque propose deux fonctions pour passer d'une donnée JSON à un objet JavaScript et vis versa.
- JSON.parse : prend une chaîne JSON et rend une valeur JavaScript
- JSON.stringify : prend une valeur JavaScript et rend une chaîne JSON