Introduction
HTML (HyperText Markup Language) permets l'écriture textuelle de documents à structure arborescente.
Historique
SGML
HTML est un sous-langage de SGML (''Standard Generalized Markup Language''). Créé en 1970 par Charles Goldfarb, Ed Mosher et Ray Lorie chez IBM, SGML devient le standard ISO-8879 en 1986.
SGML a été développé pour écrire de la documentation (plusieurs milliers de pages) avec le slogan : "Séparer le fond de la forme".
En SGML, un document est essentiellement représenté par un arbre, et chaque noeud de l'arbre est représenté par une balise.
Une balise peut contenir du texte, ou d'autres balises. Les noms des balises ne sont pas à priori fixées: on peut donc définir son propre langage SGML pour ses propres besoins.
Gràce à sa flexibilité, ce méta-langage a été utilisé par l'administration US, les militaires, l'aéronautique, mais aussi en Europe avec le CERN.
HTML et XML
HTML et XML sont à l'origine des "applications" SGML.
HTML est spécialisé pour les documents hypertextes, et créé en 1990 au CERN. Il possède au départ un ensemble restreint de balises. Cet ensemble de balises a évolué au début de façon anarchique sous l'impulsion des navigateurs internet.
Finalement, en 1994 un consortium est créé pour coordonner le développement du langage HTML: le W3C. Aujourd'hui encore, ce consortium coordonne de nombreux aspects du web. Par exemple, le tout nouveau HTML5.
XML (Extensible Markup Language) est un méta-langage comme SGML, créé par un groupe de travail vers 1998. L'objectif est en quelque sorte plus général que SGML: l'idée n'est plus simplement de stocker des documents formattés, mais de pouvoir stocker n'importe quel type de donnée sous forme textuelle et arborescente. Muni d'une syntaxe beaucoup plus strict que HTML, il est aussi muni de la notion d'espace de nom (namespace) afin de pouvoir mélanger dans un document XML donnée des "langages XML" différents. Par exemple, on trouve
- XHTML : version XML de HTML
- SVG : pour faire du graphique
- MathML : représentation de formules mathématiques
- SOAP : protocole d'échange de données par HTTP
Les espaces de noms permettent de placer par exemple du SVG et du MathML dans un fichier XHTML sans confusion de balises.
Versions
HTML a connu plusieurs versions, avec une gestion des balises plus ou moins strict.
- 1991: HTML
- 1995: HTML 2.0
- 1997: HTML 3.2
- 1999: HTML 4.01
- 2000: XHTML 1.0
- 2014: HTML5
Les quatre premières versions étaient assez laxistes sur l'obligation de fermeture de balises. Par exemple, une liste d'items pouvait être écrite comme suit:
Cela posait pas mal de problème de compatibilités entre les navigateurs. Afin de résoudre le problème, en 2000 le langage XHTML est proposé: basé sur XML, il impose une gestion plus strict des balises et oblige en particulier à explicitement fermer toutes les balises ouvertes:
Si XHTML a résolu ce problème particulier, son absence totale de flexibilité l'a rapidement rendu inutilisable pour les développement récents de l'internet et l'introduction de fonctionnalités avancées telles la vidéo ou le PDF en natif. Après d'apres débats entre les acteurs en présence sur le choix des outils standards qu'un navigateur doit ou ne doit pas avoir (en particulier les questions de codecs vidéo propriétaires ou libres), la cinquième version de HTML a finalement été adoptée en 2014. Elle permets au choix une présentation à la XML, ou plus souple.
Plugins : disparition en cours
L'un des corollaires de l'arrivée de HTML5 est la disparition à terme des plugins. Dès 1995, ces ajouts logiciels aux navigateurs permettaient, à cette belle époque du web 1.0, d'intégrer des formats de données supplémentaires dans les pages afin de les rendre plus dynamiques, ou de leur offrir plus de fonctionnalités. On peut par exemple nommer Flash, les applets Java, PDF, ou encore Silverlight.
La situation actuelle ne tourne pas vraiment en leur faveur. Par exemple, les plugins sont abandonnés dans IE10/Metro et sur mobiles et tablettes.
Au niveau des applications:
- Les applets Java sont essentiellement moribonds
- Flash: Adobe abandonne le développement sur mobile et se recentre sur le HTML5 natif, celui-ci permettant de faire au moins aussi bien...
- Silverlight: son développement est arrêté par Microsoft
- PDF est maintenant intégré nativement dans Chrome, Firefox, et la derniere mouture du navigateur de Microsoft.
Structure générale d'un fichier HTML
Un arbre HTML est toujours composé d'une racine html suivie de
deux fils
head, qui contient les méta-données du document etbody, qui contient le corps du fichier.
Le document contient en outre une ligne DOCTYPE indiquant la
version du langage HTML utilisé (et donc la syntaxe à attendre).
On peut par ailleurs ajouter des
commentaires entre les balises spéciales
Enfin, les balises peuvent contenir des attributs, qui vont se trouver
entre les symboles "<" et ">"
Un attribut est toujours une chaine de caractères. Chaque balise HTML
possède un certain nombre d'attributs valides possible.
Un fichier HTML simple est par exemple: Note: l'indentation et les sauts de ligne sont uniquement présents pour la lisibilité du fichier, ils ne sont pas pris en compte par le navigateur internet.
DOCTYPE
Une list des entêtes DOCTYPE en fonction de la version de HTML se trouve par exemple sur le site du W3C. De manière non-exhaustive, on peut donner:
- Comme déja vu, pour HTML5
- XHTML (sans support pour les frames)
- HTML 4.01 (définition souple: "transitional")
Vous noterez des addresse finissant par .dtd: il s'agit du fichier
de spécification de la sous-grammaire HTML utilisée.
De fait, le navigateur n'a pas besoin de les consulter: il connait les règles en interne et est capable de parser une page suivant chacune des grammaires standards. Si néanmoins vous ouvrez l'une de ces specifications, vous retrouverez les noms de balises, quels fils et quels attributs chaque balise est autorisée à avoir.
Sans rentrer dans les détails de la construction d'un tel fichier (que vous êtes fortement invité à aller consulter au moins une fois pour savoir à quoi cela ressemble !), il faut garder en tête qu'il s'agit du coeur de la compatibilité entre les pages internet et les navigateurs. Il est donc très important de se conformer aux spécifications lors de l'écriture de page internet. Afin de les tester, il existe des outils hors-ligne, téléchargeable par exemple dans la rubrique Outils sur ce site, ou directement en ligne sur le site du W3C.
Encodage des caractères
Vous aurez noté à la ligne 4 de l'exemple une référence au codage des caractères
Il s'agit d'une information essentielle pour le navigateur: en effet, un fichier HTML est d'abord un fichier texte, avec potentiellement des accents et des symboles. En mémoire, ce fichier est représenté avec des octets, c'est à dire des suites de bits (0 ou 1). Il faut donc décoder ces octets pour savoir à quel caractère ou symbole ils font référence.
Le premier standard proposé (en 1963) encodait sur 7 bits et donc permettait 128 symboles. Dans un monde numérique essentiellement anglo-saxon, c'était parfaitement suffisant pour
- Les majuscules et minuscules
- Les chiffres
- Les quelques symboles usuels: = * & ^ # % ; ...
- Quelques caractères de contrôle: CR, LF, TAB, BEL, ...
La table au complet, dans toute sa majesté, se trouve un peu partout sur internet, par exemple ici.
Plus tard, on a étendu la table avec le 8ième bit, ce qui donnait 128 caractères supplémentaires pour prendre en compte les caractéristiques d'une langue, ou d'un groupe de langues. Par exemple:
- ISO 8859-1 (Latin-1) : français, espagnol, allemand...
- ISO 8859-2 : polonais, tchèque, hongrois...
- ISO 8859-xx développés et maintenus de 1982 à 2004
C'est évidemment non-exhaustif, et il y a tout une zoologie de codages avec plus de 1000 encodages "standards".
Dans un soucis d'unification et d'interopérabilité, le format Unicode a été développé. Chaque caractère ou symbole se voit attribuer un numéro unique (code point). Chaque numéro acceptent plusieurs formes de transformation (plus ou moins précise) suivant le nombre de bits que l'on est prêt à utilisé:
- UTF-8 : sur 8 bits
- UTF-16 : sur 16 bits
- UTF-32 : sur 32 bits...
L'adoption de l'unicode sur internet est sans appel:

(tiré d'un post de 2012 sur le googleblog)
Caractères spéciaux et HTML
En HTML, il est possible de représenter tout caractère en utilisant son code. Pour la lettre A:
- Décimal:
A - Hexadécimal:
A
Notez le point virgule à la fin. Tous les symboles existant ainsi que leur représentation sont listés par exenmple sur w3school.
De nombreux caractères usuels ont cependant un nom mnémotechnique. Par exemple: Un reader-digest est par exemple ici, mais sur la page de w3school les raccourcis sont indiqués quand ils existent.
Note: Un corollaire de la syntaxe HTML est que les caractères <, > et & ne peuvent pas être représentés tels quels: ils doivent impérativement être échappés (c'est à dire écrit en utilisant la syntaxe ci-dessus)
Accessibilité
Lors de la conception d'une page internet, ou plus généralement d'un site complet, il faut garder en tête la pluralité des types d'utilisateurs :
- personnes handicapées
- seniors
mais aussi les fonctionnalités des interfaces utilisées:
- smartphone (donc avec petit écran, sans souris)
- tablette (grand écran, sans souris)
- télévision (avec potentiellement couleurs dégradées / absentes)
- navigateur texte (présentation de la structure)
Il est donc impératif d'avoir une approche agnostique quand à la présentation du contenu: il faut qu'une page internet se comporte bien, en toute circonstance:
- sur la forme : utilisable avec une petite taille d'écran, en l'absence de couleur, sans accès à une souris
- sur le fond : un document structuré, c'est à dire pour lequel on puisse inférer la nature de chaque élément à partir de son type, et non à partir de sa couleur, sa taille... Un titre doit donc utiliser une balise de titre, un paragraphe une balise de paragraphe, etc.
L'accessibilité est quelque chose qui a été réfléchi par le W3 (encore eux!), avec une série de recommandations de bonne conduite (voir aussi la page wikipedia en français, bien faite).
Rapide documentation
Dans ce cours, nous allons utilisé le HTML 5.
Un document HTML est shématiquement sous la forme
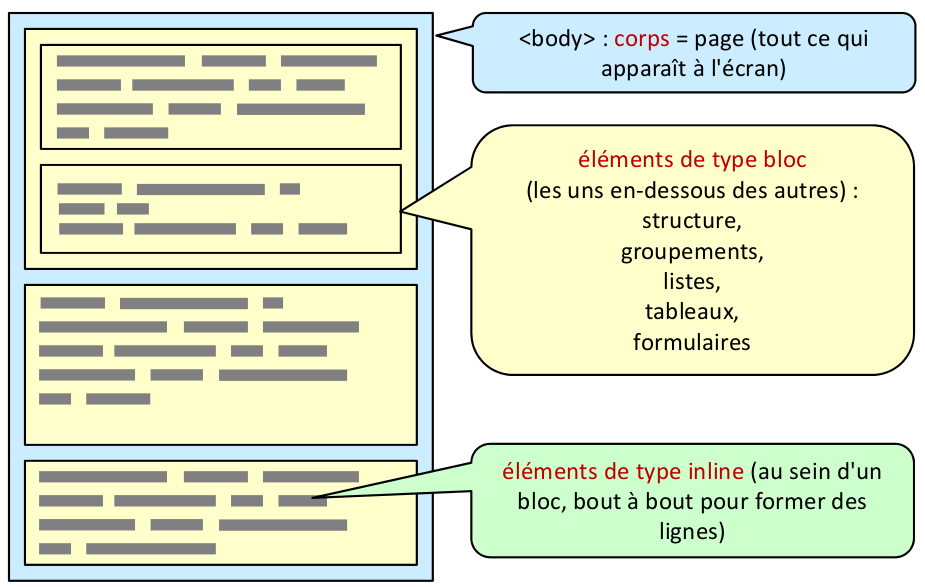
Éléments de type bloc
Un document HTML doit être le plus sobre possible en terme de balises, et chaque balise doit correspondre exactement au sens que doit avoir son contenu: une balise de titre pour un titre, une balise de section pour une section, ...
Structure générale
- <section> : section, partie du document
- <h1>, ..., <h6> : titre de section (de différents niveaux)
- <article> : article de blog, commentaire
- <aside> : section supplémentaire (“encadré”)
- <nav> : section qui contient des liens de navigation
- <header>, <footer> : en-tête et pied de page
- <address> : information de contact
- <p> : paragraphe
- <pre> : bloc de code
- <blockquote> : citation
- <div> : groupement quelconque
Listes et tableaux
- Unordered list
- Ordered list
- Descriptions
- Tableaux
Formulaires
- <form> : formulaire
- <input> : champ de saisie ; type donné par attribut type
- text, email, password, date, range, checkbox, radio, file, submit...
- <textarea> : zone de texte multi-lignes
- <select> : liste de choix
Multimédia
- Images
- Videos
- Audio
- Dessin dynamique: <canvas>
- <figure> : figure. Exemple:
Autres
Enfin, un document HTML5 peut inclure des fragments écrits dans deux autres langages XML :
- <svg> : image vectorielle SVG
- <math> : formule mathématique MathML
Éléments inline
- <a href="addresse_du_lien"> : lien
- <em>, <strong> : emphase
- <cite> : titre d'une œuvre
- <quote> : citation (mots, phrase)
- <abbr> : abréviation
- <time> : date et heure
- <code>, <var> : fragment de code, variable
- <sup>, <sub> : exposant, indice
- <span> : inline quelconque
Liens: notion d'URL
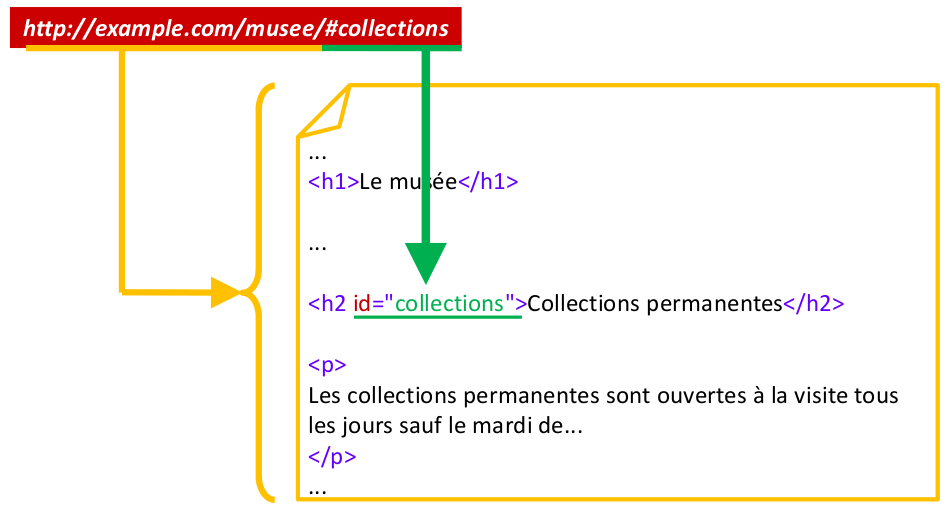
Une URL (Uniform Resource Locator) est une chaîne de caractères qui identifie une ressource. Elle a la forme

Autres exemples:
- ../enseignement/ (URL relative)
- mailto:Benoit.Valiron@centralesupelec.fr (mail)
- file:///home/valiron/MementoLatex.pdf (fichier local)
- https://www.google.com (protocol HTTP avec encryption SSL)
- ftp://ftp.gnu.org (protocol FTP)
On peut faire référence à une balise dans une page HTML si celle-ci possède un attribut ID (attention, une attribut ID est à priori unique pour une page donnée)